GPT-4主导的「谁是卧底」桌游!对话逼真,类人属性有待提升 本文介绍了一项有关GPT-4参与桌游「Spyfall」的研究。通过让GPT-3.5和GPT-4参与游戏测试其类人属性,一支韩国团队引发了对生成式AI研究的新思考。「Spyfall」是一个黑帮题材的桌游,玩家需要通过言语互动揭示「卧底」的身份,适合朋友聚会。该研究也探讨了AI在类人交流方面的发展空间。... AI工具箱3年前
23岁华人博士揭开22年历史漏洞,引爆网络热议 AIGC动态欢迎阅读本文以斯坦福大学年仅23岁的华人博士成功修复一个已存在22年的bug为题。这个新闻在网上一夜爆红,受到许多网友的关注和赞赏。该bug自2002年起隐藏在Firefox浏览器核心代码中,一直未被发现。原文由新智元发布,文章详细描述了这位年轻华人博士的修复过程及其意义。想了解更多详情... AI工具箱3年前
14个提高Prompt质量的有效方法 <img src=""> AIGC动态欢迎阅读 本文原题为:《Effective Prompt: 编写高质量Prompt的14个有效方法》。关键词包括知乎、模型、任务、答案和问题。文章来源于夕小瑶科技说,字数为13133字。夕小瑶科技说分享了知乎用户@Maple小七、... AI工具箱3年前
MetaMath:革新数学推理的语言模型,探索大规模模型的逆向思维 欢迎阅读AIGC动态 本文原标题为:MetaMath:新数学推理语言模型,探讨训练大型模型的逆向思维能力。 关键词:数据、模型、华为、问题、准确率。 文章来源:机器之心。 全文字数:6874字。 内容摘要:数学推理在大型语言模型的评估中扮演着至关重要的角色。当前常用的数学推理数据集样本量不足,问题多... AI工具箱3年前
中国科学院:GPT-4推理更接近人类思维,提出「思维传播」,类比CoT胜出【即插即用】 这篇文章介绍了中国科学院和耶鲁大学联合研究提出的新框架「思维传播」,旨在让大型神经网络模型(如GPT-4、PaLM等)具备类比思考的能力,从而更接近人类推理的方式。这一框架对于解决大型模型在复杂、多步推理任务上常常失败的问题具有重要意义。文章提到了这些巨型神经网络模型在少样本学习能力上已经展现出惊人... AI工具箱3年前
你的数据库比 Ruby 运行得还慢 AI前线动态:慢的不是 Ruby,而是你的数据库原文标题:慢的不是 Ruby,而是你的数据库关键词:数据库、性能、问题、报告、代码文章来源:AI前线字数:17927字内容摘要:作者Sergio De Simone,译者明知山,策划丁晓昀。许多人不断抱怨 Ruby 运行缓慢。确实,它的表现不佳,然而并... AI工具箱3年前
FRESHLLM:紧贴时事,搜索体验提升 AIGC动态欢迎阅读 此文源自机器之心报道,介绍了FRESHLLM在与谷歌搜索竞争活跃程度方面的表现。FRESHLLM紧跟时事,减少幻觉,提供更精准的信息。 关键词:问题、研究者、模型、证据、知识。 文章内容由机器之心撰写,篇幅为7275字。其中提到,LLM编辑部更新了知识,与谷歌搜索展开竞争。目前... AI工具箱3年前
海尔布隆三角问题的更小上界终于被找到 AIGC动态欢迎阅读 原文题目:沉寂四十年,海尔布隆三角问题找到了更小的上界 关键词:角形,海尔,问题,数学家,面积 文章来源:机器之心 文章字数:7793字 内容摘要:机器之心编译编辑:赵阳一项新的证明打破了几十年来海尔布隆三角问题的上界,虽然数值上只是突破了一点,但却是三角问题的一大步。假设有一... AI工具箱3年前
解开50年谜题:制作莫比乌斯环所需最短纸带长度是多少? 文章介绍了一个关于制作莫比乌斯环所需纸带最短长度的数学谜题的研究。莫比乌斯带是一种特殊的数学结构,简单的构造方式却具有复杂的性质,一直以来吸引着数学家们的兴趣。最近的研究解决了关于制作莫比乌斯环所需纸带最短长度的问题。阅读原文可以了解更多详情。文章来源于机器之心,作者微信是almosthuman20... AI工具箱3年前
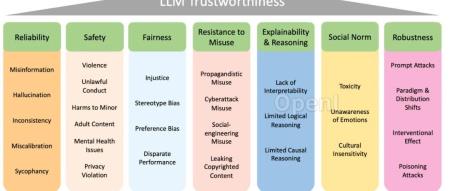
七大维度评估大语言模型可信度 欢迎阅读AIGC动态 本文原题为:“如何评估大语言模型是否可信?这里总结了七大维度。” 本文讨论关键词包括:模型、维度、类别、研究者、问题。 文章来源于机器之心。 全文共6813字,主要由刘扬和Kevin Yao撰写。文章主要提出了7个关键维度,用以全面评估大型语言模型的可信度。在实际部署中,“对齐... AI工具箱3年前
苹果官方回应iPhone 15 Pro发热问题,辟谣「高铁因超员无法发车」,华为将于中秋发表Mate60新品。 欢迎阅读AIGC动态原标题:苹果对iPhone 15 Pro发热问题作出回应,官方澄清「高铁因超员无法发车」、「华为中秋发Mate60」为误传关键词:华为、公告、票房、国庆、问题文献来源:爱范儿内容字数:6376字内容摘要:苹果谈及iPhone 15 Pro发热问题:是由于iOS 17 bug,而非... AI工具箱3年前
深度解读图灵原理:探寻反证法的威力 AIGC动态欢迎阅读 原标题:重温图灵原理,感受反证法的力量 关键词:问题、字符串、算法、对角线、反证法 文章来源:机器之心 内容字数:6293字 内容摘要:机器之心编译选自量子杂志编辑赵阳,图灵原理揭示了人类永远不可能做到可知而全知。本文将阐释图灵是如何基于对角线证明,从反证法的角度对图灵原理进行... AI工具箱3年前
ChatGPT正式联网,提供回答来源查询功能 AIGC动态欢迎阅读原文标题:ChatGPT终于正式联网,还能给出答案出处核心词汇:功能、答案、用户、问题、链接来源:机器之心字数:1912字内容摘要:经机器之心报道编辑张倩整理,OpenAI宣布了一项重大消息:ChatGPT已正式实现联网。以往仅能回答2021年9月之前问题的ChatGPT,因为训... AI工具箱3年前
体验 GPT-4V(ision) 带来的全新视野 本文是从AI范儿转载的文章,介绍了对GPT-4V(ision)图像输入功能的初步印象。文章中分享了团队对GPT-4V进行的一系列实验和测试,展示了模型在不同方面的表现和挑战。作者指出,读者的测试结果会根据提出的问题和使用的图像而有所不同。想要了解更多详情,请阅读原文:对 GPT-4V(ision) ... AI工具箱3年前
三大科技巨头的华裔研究员们正在讨论什么?对话实录 <img src=""> 人工智能领域动态报道 原文标题:OpenAI、Google和Meta的华裔研究员们的最新见解|对话内容整理 关键词:模型、幻觉、问题、代码、人类 文章来源:人工智能学家 字数:6864字 简要内容:一场在硅谷举办的GenAI大会中,被安排在“... AI工具箱3年前
Meta提出新方法,准确率超过ChatGPT,降低大模型幻觉 AIGC动态欢迎阅读本文转载自量子位,原文标题为“长文本信息准确率超过ChatGPT,Meta提出降低大模型幻觉新方法”,探讨了研究人员如何通过新方法提高大型模型的信息准确率,避免幻觉输出。Meta AI实验室引入了一种名为“验证链”(CoVe)的链式方法,使得Llama-65B模型的准确率得到显著... AI工具箱3年前
ChatGPT在课堂上帮助学生表现优异,教授质疑:使用是否为作弊? <img src=""> AIGC动态欢迎阅读 原文标题:Nature|ChatGPT带动学生在课堂上表现出色,教授斥责:我用可以,你们用就是作弊! 关键词:政策,学生,研究人员,教育工作者,问题 文章来源:新智元 内容字数:10068字 内容摘要:根据最新研究,发现... AI工具箱3年前
如何看待国内顶级模型层和中间层,以及大型模型在实际应用中的落地情况? AIGC动态欢迎阅读原文标题:国内顶尖模型层和中间层,对大模型落地应用的看法关键词:模型、中间层、开发者、向量、问题文章来源:创始人公园文章长度:28250字内容摘要:本文记录了国内一线专家关于模型层和中间层的讨论。内容涵盖了当前国内大型模型和应用生态的发展现状、应用落地的趋势分析、开发者和创业者所... AI工具箱3年前
上交AI数学开源模型震撼登顶阿贝尔排行榜 欣赏AIGC的最新动态 原文标题:打破美国AI公司霸榜,上交AI数学开源模型阿贝尔排行榜首 关键词:模型、数学、数据、任务、问题 文章来源:机器之心 文章字数:5806字 内容摘要:机器之心报道,机器之心编辑部以ChatGPT为代表的大型模型产品引领了一场新的产业浪潮,激发了国内外各机构积极投入相关... AI工具箱3年前
深呼吸:谷歌DeepMind利用大型语言模型生成Prompt,AI感知AI更胜一筹 近日,新智元报道了谷歌DeepMind提出的新优化框架OPRO,该框架可以通过自然语言描述来引导大型语言模型逐步改进解决方案,实现各种优化任务。具体来说,DeepMind利用大型语言模型生成Prompt提示词,如在命令中加入“深呼吸”,就可以使模型在某项任务中表现更出色。通过这种方式,模型在GSM8... AI工具箱3年前
MAmmoTH开源:挑战GPT-4,参数量超越34B,平均准确率最高提升29% AIGC动态欢迎阅读 原标题:34B参数量超越GPT-4!「数学通用大模型」MAmmoTH开源:平均准确率最高提升29% 关键词:模型,数据,数学,问题,研究人员 文章来源:新智元 内容字数:9208字 内容摘要:新智元报道编辑:LRS【新智元导读】数学通才「猛犸」模型为开源语言模型带来了「推理春天... AI工具箱3年前
深入探讨智能科学:意识的全面介绍 欢迎阅读AIGC动态 原标题:智能科学导论(46)——意识概述 关键词:报告、意识、问题、科学、神经 文章来源:人工智能学家 内容字数:10838字 内容摘要:意识的起源与本质是科学中最重要的问题之一。在智能科学领域,意识问题具有特殊的挑战性。意识是一种复杂的生物现象,哲学家、医学家和心理学家对意识... AI工具箱3年前
P vs NP问题仍然是猜想,有99.9999%的概率尚未解决 文章标题为“AIGC动态欢迎阅读”,介绍了关于P vs NP问题的一个新闻。最近有消息称,一些机构的研究人员通过严格推理成功让GPT-4得出了P≠NP的结论。这一进展被描述为研究人员通过Chatgpt-4进行某种模式的推理,从而得到了P≠NP的结论,否定了这一数学和理论计算机界的问题。然而,对于他们... AI工具箱3年前
使用AI神器ChatGPT的90%以上用户未掌握的实操技巧,值得藏起来的学习手册 本文介绍了AI技术ChatGPT的使用手册。自2022年11月30日推出以来,在国内受到广泛关注。文章强调人类仍然比AI更强大,ChatGPT的逻辑简单,交互体验符合人性,只需通过对话即可使用。然而,并非每个人都能充分利用ChatGPT。作者承诺通过本文教会读者如何掌握ChatGPT的使用方法。如需... AI工具箱3年前
陶哲轩预言成真:GPT-4成功证明P≠NP!利用97轮「苏格拉底式推理」揭开世界数学难题 这篇文章介绍了GPT-4通过97轮「苏格拉底式推理」成功得出了P≠NP的结论,实现了陶哲轩的预言。文章摘要指出了此次研究的关键字包括问题、多项式、结论等,而这一研究成果来自于微软亚洲研究院、北大、北航等机构的研究人员共同努力。这一成果的背后是对数学定理的深度研究,展示了大语言模型在数学领域的潜力。 ... AI工具箱3年前
微软超强小模型发布引发「教科书级」数据能有多大作用? 欢迎阅读AIGC动态原文标题:「教科书级」数据在数据中的作用有多大?微软超强小型模型引发热议关键词:数据、模型、论文、问题、团队文章来源:机器之心内容字数:3655字内容摘要:随着大型模型引发新一轮AI热潮,人们开始思考:大型模型的强大能力源自何处?目前,大型模型一直在不断增加的「大数据」的推动下发... AI工具箱3年前
Rust社区创始人回应:别Call我了,我也救不了! AI前线最新动态 原文标题:人红是非多!Rust社区冲突不断,创始人表示无力挽回! 关键词:团队、项目、问题、类型、语言 信息来源:AI前线 字数统计:8810字 内容概要:专栏作者 Tina 和核子可乐分析了Rust社区存在的管理问题。他们讨论了如果Rust采用创始人领导的方式管理是否更为良好的可... AI工具箱3年前
揭秘Meta计划:2024年启动训练,打造下一代大型模型GPT-4 最新报道显示,Meta计划推出下一个以GPT-4为标准的大型语言模型,并计划于2024年开始进行训练。作为领先的科技公司,Meta在人工智能研究领域走在了前列。近期,一系列大型语言模型如Llama和Llama 2相继问世,尤其是Llama 2的商业可行性,为开源社区带来了许多便利,大模型的时代似乎已... AI工具箱3年前
谷歌DeepMind发布新论文:AI设计的大语言模型提示词效果超越人类 这篇文章介绍了谷歌DeepMind团队最新发现的关于大语言模型的研究成果。他们发现,通过在提示词中加入“深呼吸”,结合已有的“一步一步地想”,能显著提高大型模型在数据集上的表现。这种最有效的提示词是由人工智能自主发现的。文章来源为夕小瑶科技说,作者微信号为xixiaoyaoQAQ,主要涉及人工智能领... AI工具箱3年前
如何应对大型语言模型中的“幻觉”?腾讯AILab深度探讨检测、解释和缓解策略 这篇文章是从人工智能学家来源的,主要介绍了关于大型语言模型中“幻觉”问题的研究成果。虽然大型语言模型在各种任务中表现出色,但存在幻觉现象:有时会生成与输入不符、与上下文相矛盾或与世界知识不一致的内容。这对其在实际应用中的可靠性构成挑战。文章指出了检测、解释和减轻幻觉的努力,重点关注大型语言模型带来的... AI工具箱3年前
谷歌DeepMind研究表明,大模型通过“深呼吸”与数学提升8分,在AI自主设计提示词方面超越人类 欢迎阅读AIGC动态 原标题:谷歌DeepMind发现AI自己设计提示词效果胜过人类,大型模型通过“深呼吸”数学再提高8分 关键词:模型,提示,论文,问题,团队 文章来源:量子位 内容字数:3950字 内容摘要:最新研究发现,AI大型模型在处理GSM8K数据集时,通过在提示词中加入“深呼吸”,结合“... AI工具箱3年前
谷歌CEO桑达尔·皮查伊:谷歌25周年:搜索仍是核心,AI是最大变革 AIGC动态欢迎阅读 原标题:谷歌CEO桑达尔·皮查伊:谷歌25周岁,搜索仍是核心,AI是最大变革 关键词:人工智能,报告,问题,产品,技术 文章来源:人工智能学家 内容字数:10775字 内容摘要:1998年9月4日,谢尔盖·布林和拉里·佩奇在加州硅谷门罗帕克,正式创立Google,也掀起了互联网... AI工具箱3年前
GitHub热度首屈一指:开源GPT-4代码解释器,支持自定义Python库安装和本地终端运行 本篇文本介绍了开源版GPT-4代码解释器在GitHub热榜上的登顶情况。该代码解释器可以安装任意Python库,并在本地终端运行。文章内容来源于量子位,作者是QbitAI。该解释器不仅具备GPT-4原有的功能,还增加了联网功能。之前因为“断网”问题引起了一些争议,但现在已经找到了解决办法。感兴趣的读... AI工具箱3年前
评估LLM安全机制的利器:数据集派上用场 AIGC动态欢迎阅读 原标题:「不要回答」,数据集来当员,评估LLM安全机制就靠它了 关键字:模型,问题,风险,数据,类别 文章来源:机器之心 内容字数:4705字 内容摘要:机器之心专栏机器之心编辑部叶文洁打开结果文件,人类第一次读到了来自宇宙中另一个世界的信息,其内容出乎所有人的想象。三体文明以... AI工具箱3年前
陶哲轩用大型模型协助解决数学问题:生成代码、编辑LaTeX公式都非常便捷 这则文章讨论了数学家陶哲轩如何利用大型模型来辅助解决数学问题,并分享了他使用ChatGPT的实验结果。陶哲轩尝试使用ChatGPT生成可以采用LaTeX表达式的程序代码,在与网友的交流中得到了一些使用技巧建议。最终,他成功生成了一段可在VSCode中使用的代码。这篇文章来自机器之心,提供了更多信息和... AI工具箱3年前