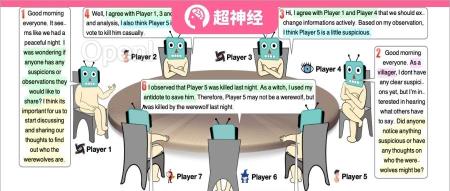
本文介绍了清华大学研究团队提出的一种用于交流游戏的框架,展示了大语言模型在经验中学习的能力,并发现大语言模型具有非预编程的策略行为。他们发现,大语言模型在玩狼人杀等游戏时表现出信任、对抗、伪装和领导等策略,这为进一步研究大语言模型在交流游戏中的表现提供了新的视角。与此同时,文章还提供了原文链接以及作者的联系信息供读者参考。如果想了解更多内容,可以查看原文链接。
如果您需要获取完整的PDF文件,请回复「狼人杀」获取相关信息。