PaLM 2数学性能提升至6%,DeepMind新研究揭示「合成数据」是通往AGI关键 本文介绍了最新研究表明,利用合成数据可以显著提升AI模型在数学问题解决和代码生成方面的能力。研究人员发现,利用AI系统自己生成数据进行训练可以带来巨大的好处。特别是在MATH高级推理和APPS编码基准测试中,使用PaLM-2模型进行测试后,发现其性能比仅在人类数据上微调的模型要好得多。这一发现引发了... AI工具箱3年前
字节利用RLHF 2%的算力,成功抑制LLM有害输出,提出LLM遗忘学习 <img src=""> AIGC动态欢迎您的阅读 原标题:用RLHF 2%的算力实现LLM停止有害输出,字节跳动提出LLM遗忘学习 关键词:侵权、样本、政策、字节跳动、报告 文章来源:机器之心 内容字数:5422字 内容摘要:随着大型语言模型(LLM)的发展,从业者... AI工具箱3年前
NeurIPS 2023 | 人类智能启发,全新数据增强范式GIF框架发布 AIGC最新动态原标题:NeurIPS 2023 | 创新数据集扩增框架助力人工智能发展关键词:数据集, 字节跳动, 深度学习模型, 样本, 信息丰富度文章来源:机器之心字数:5076字内容摘要:机器之心编辑部撰写的这篇关于 NeurIPS 2023 的文章介绍了新加坡国立大学和字节跳动团队提出的数... AI工具箱3年前
3个样本、1个提示搞定LLM对齐,提示工程师:全部变得清晰明了 <img src=""/> 欢迎阅读AIGC动态 原文标题:微调都不需要了?3个样本、1个提示就能完成LLM对齐,提示工程师:全都回来了 关键词:报告, 基础, 模型, 研究者, 样本 文章来源:机器之心 内容字数:8670字 内容摘要:机器之心报道指出,进行LLM对... AI工具箱3年前
微软通过「提示工程」让GPT-4成医学专家,测试准确率首次超过90% 欢迎阅读AIGC动态 原标题:微软仅凭「提示工程」让GPT-4成为医学专家!超过一众高度微调模型,专业测试准确率首次超过90% 关键词:样本、研究人员、示例、提示、数据 文章来源:量子位 内容字数:4414字 内容摘要:最新研究显示,微软的最新研究证明了提示工程的巨大威力——GPT-4无需额外微调,... AI工具箱3年前
苏黎世理工与Meta AI联合打造小型模型架构,助力大模型表现提升 这是一篇介绍AIGC动态的文章。文章指出,大模型在自我改进方面存在一定的局限性,因为它们无法准确判断原始答案是否错误以及是否需要改进。最近,苏黎世理工与Meta AI提出了一种名为ART的策略,即提出问题、调整和信任的方法,通过对初步输出和改进输出进行评估,确定最终的答案。在两个多步推理任务中,AR... AI工具箱3年前
材质界的”ImageNet”:大规模6维材质实拍数据库OpenSVBRDF发布【SIGGRAPH Asia】 这篇文章是关于材质领域的一项重要进展。文章介绍了一项名为OpenSVBRDF的大规模6维材质实拍数据库的发布,这被称为材质界的ImageNet。材质在现实物体与光线之间的复杂物理交互中起着关键作用,而SVBRDF则是视觉计算中不可或缺的组成部分。随着对高精度、多样化数字材质外观的需求不断增加,构建这... AI工具箱3年前
字节跳动和华东师大联合研究:小模型如何实现上下文学习?提出自进化文本识别器 本文是关于字节跳动和华东师大联合提出自进化文本识别器的内容。文章指出大型语言模型能够通过上下文学习从少量示例中学习,但这种现象只能在大模型上观察到。为了研究小型模型的上下文学习能力,在场景文本识别任务上进行了探索。场景文本识别面临着多种挑战,如不同场景、文字排版、形变、光照变化等,训练统一的文本识别... AI工具箱3年前
腾讯揭秘:AI大模型优化QQ浏览器搜索功能 AIGC动态欢迎阅读 原标题:用AI大模型「改造」QQ浏览器搜索,腾讯独家揭秘 关键字:模型、腾讯、语义、效果、样本 文章来源:机器之心 内容字数:15167字 内容摘要:本文介绍了腾讯QQ浏览器搜索应用部利用AI大模型对搜索进行改进的独家揭秘。文章首先回顾了搜索引擎技术的发展历程,从文本索引到深度... AI工具箱3年前
13B模型揭秘:如何全面超越GPT-4? AIGC动态欢迎您的阅读 原标题:13B模型是否真的超越了GPT-4?背后的内幕揭秘 关键词:样本、基准、测试、本文、数据 文章来源:机器之心 内容字数:5526字 内容摘要:机器之心报道编辑:陈萍,您的测试集信息是否在训练集中泄漏?一个参数量为13B的模型竟然战胜了顶尖的GPT-4?如下图所示,并... AI工具箱3年前
过多强调「对齐」可能会对「图对比学习」造成负面影响——最新研究发现 <img src=""> 标题:AIGC动态欢迎阅读 最新研究来自人民大学指出,在图对比学习中,过度强调「对齐」可能会产生负面影响。尽管更好的数据增强可以提高模型在下游任务中的泛化能力,但同时也可能削弱对比学习的原始性能。近年来,由于数据量的增加和标签信息的不足,自监... AI工具箱3年前
AI训练数据版权保护:三篇论文探讨水印技术的应用 欢迎阅读AIGC动态 原标题:当数据成为「生产资料」,三篇论文总结如何用水印技术保护AI训练数据版权 关键词:数据,水印,样本,模型, 文章来源:机器之心 内容字数:37614字 内容摘要:本文是机器之心原创作者Jiying编辑的文章。在本文中,作者深入探讨了为什么在AI训练数据中添加水印的重要性。... AI工具箱3年前
上海交通大学新款大模型在部分任务上超越了GPT-4,模型数据全部开源 《AIGC动态》欢迎您的阅读 原文标题:上海交通大学研究组开发的新一代AI模型在某些任务上超越GPT-4,模型数据已公开发布 关键词:模型、场景、标准、数据、样本 文章来源:量子位 内容字数:8894字 内容摘要:Pengfei Liu自凹非寺量子位投稿 | 公众号QbitAI。在评估大型模型性能时... AI工具箱3年前
美国阿贡国家实验室推出快速自动扫描套件 FAST,助力显微技术实现「快速阅读」 欢迎阅读AIGC动态原标题:美国阿贡国家实验室发布快速自动扫描套件 FAST,助力显微技术「快速阅读」成为可能关键词:覆盖率,图像,样本,测量,显微镜文章来源:HyperAI超神经内容字数:9068字内容摘要:超神经在北京市的门广场看到红色国旗升起,便可快速理解该句含义。科学研究是否也能遵循这一原则... AI工具箱3年前
谷歌发布自适应提示方法,让提示工程告别烦恼! AIGC动态欢迎阅读原文标题:再见了,提示~ 谷歌发布自适应提示方法,从此告别提示工程!关键词:样本, 任务, 问题, 解读, 答案文章来源:夕小瑶科技说内容总字数:5633字内容摘要:夕小瑶科技说原创作者 | 谢年年、ZenMoore大模型虽好,但存在一个令人困扰的问题:大模型的回答质量取决于我们... AI工具箱3年前
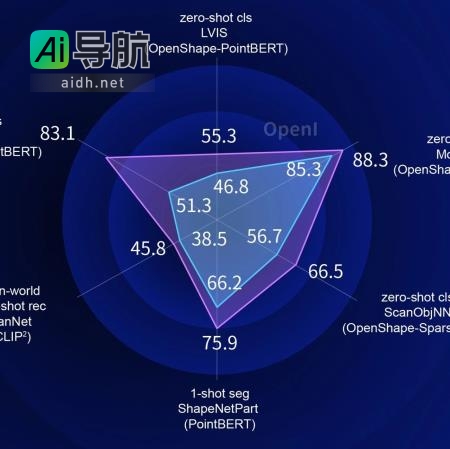
智源和清北联手,发布10亿参数Uni3D视觉大模型,助你从「最强2D」升级到「最强3D」 本文介绍了智源、清华和北大联合发布的10亿参数的3D视觉通用模型Uni3D,该模型在主流3D视觉能力上表现出色。文章指出计算机视觉是人工智能的眼睛,三维视觉的研究使机器具备了探知真实空间纵深与距离的能力。发展三维视觉模型对于让机器在复杂场景中更智能地路径规划和与周边精准交互具有重要意义。近日,智源研... AI工具箱3年前
GPT-4之外,13B评估大模型Auto-J明,评论技驾驭更胜一筹 欢迎阅读AIGC的最新动态 原文标题:评论能力强于GPT-4,上交开源13B评估大模型Auto-J 关键词:模型、场景、标准、数据、样本 文章来源:机器之心 字数:7497字 内容摘要:随着生成式人工智能技术的迅速发展,确保大型模型与人类价值观的对齐已经成为一个重要挑战。然而,目前的评估方法存在一定... AI工具箱3年前
谷歌教会大型模型自动学习1+1=2的推理规则,开启大型模型的推理之旅 AIGC动态欢迎阅读 原标题:谷歌教会模型自动学习推理规则,助力大模型实现真正的认知 关键词:规则,阶段,报告,样本,归纳 文章来源:夕小瑶科技说 内容字数:9143字 内容摘要:在学习算术的初期,我们通常通过逐步展示如1+1=2、1+2=3等示例来帮助孩子理解加法或乘法的概念,这是一种依赖于记忆和... AI工具箱3年前
清华团队揭秘GPT-4V和谷歌Bard等多模态大模型的安全漏洞? 欢迎阅读AIGC动态 原标题:清华团队成功攻破GPT-4V和谷歌Bard等模型,揭示商用多模态大模型的脆弱性? 关键词:图像、模型、样本、毒性、检测器 文章来源:机器之心 内容字数:6745字 内容摘要:最近,机器之心编辑部报道称,清华团队成功开放了GPT-4V的视觉模态。多模态大语言模型(Mult... AI工具箱3年前
谷歌提出「分步蒸馏」:超越5400亿参数的PaLM,只需80%训练数据!ACL 2023 这篇文章介绍了一种名为「分步蒸馏」的技术,该技术旨在提高小型模型的性能,从而实现在大型语言模型的应用中取得突破。相比于大型语言模型,在实际应用时,小型模型更加实用,且具有更高的内存利用效率。该技术的提出,为解决大型语言模型在资源消耗和计算资源方面的问题提供了新的思路。文章来源于新智元,您可以前往原文... AI工具箱3年前
ICCV 2023 Oral | 基于动态原型扩展的自训练方法:开放世界测试段训练技巧 欢迎阅读AIGC动态 原标题:ICCV 2023 Oral | 开放世界下的测试段训练方法:基于动态原型扩展的自训练方法 关键词:样本、原型、测试、方法、数据 文章来源:机器之心 字数:9131字 内容摘要:本文介绍一种针对开放世界的测试段训练方法,旨在提高模型的泛化能力,这是推动基于视觉感知方法应... AI工具箱3年前
HuggingFace推出的音频生成Pipeline:几行代码、几秒钟生成令人惊叹的音频样本 本文介绍了一项新的技术:HuggingFace推出的音频生成Pipeline。该技术能够通过几行代码和几秒钟的时间生成令人惊叹的音频样本。音频在日常生活中非常重要,AI技术为音频带来了全新的体验。文章提到,通过AI技术,只需输入一些文本提示就可以生成逼真的声音效果和动人的音乐。 清华大学的刘浩及其团... AI工具箱3年前
研究显示:GPT-4的API误用率超过62%,你敢用吗? 亚洲人工智能大会动态 原标题:GPT-4:使用我生成的代码需要谨慎!研究显示其API误用率超过62% 关键词:代码, 样本, 研究者, 问题, 报告 文章来源:机器之心 内容字数:8327字 内容摘要:机器之心的编辑Panda W指出,很多开发者在开发软件时已经开始依赖大型语言模型的协助,但最新研究... AI工具箱3年前