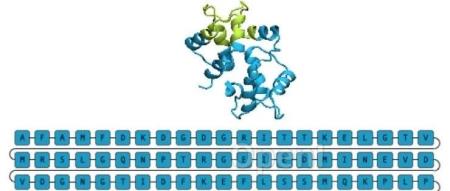
AI 动态:顶尖科学家如何运用人工智能?DeepSpeed4Science 计划利用先进 AI 系统提升科学发现本文原题为:顶尖科学家如何玩转 AI?DeepSpeed4Science:利用先进的 AI 系统优化技术实现科学发现关键词:模型、微软、序列、知乎、科学文章来源:新智元文章总字数:8778...
最近,机器之心发布了一篇关于新型LLM(Large Language Model)的文章。这篇文章介绍了一个名为vLLM的项目,它的研究团队来自加州大学伯克利分校等机构。他们开发了一种名为PagedAttention的新型注意力算法,可以帮助服务提供商以低成本、快速发布LLM服务。这篇文章仔细解释了...