谷歌Gemini卷土重来!多模态能力与GPT-4V齐名|港中文128页全面测评报告 近期,谷歌的Gemini-Pro在多模态能力方面取得了一定突破,与GPT-4V不相上下。港中文等机构在不到一周的时间内进行了评测,并发布了长达128页的报告。报告显示,在37个视觉理解任务中,Gemini-Pro展现出了与GPT-4V相媲美的能力。在多模态专有基准MME上,Gemini-Pro的综合... AI工具箱3年前
再见,汤晓鸥:致敬一代文坛巨匠 在这篇文章中,介绍了人工智能领域的两位重要科学家孙剑和汤晓鸥。他们在人工智能领域取得了重要的成就,但在不同的时间因疾病离世。汤晓鸥老师的告别仪式在上海举行,让人感慨万千。汤晓鸥老师通过他的研究工作,推动了计算机视觉技术的发展,影响了整个人工智能领域。文章中提到了他的关键贡献和与学生们的合作,展示了他... AI工具箱3年前
商汤创始人汤晓鸥逝世,享年55岁,世人缅怀 《AIGC动态》热点新闻 原标题:商汤创始人汤晓鸥逝世,享年55岁 关键词:深度学习,商汤科技,计算机实验室,算法研究,视觉技术 文章来源:量子位 字数:2938字 简要概述:商汤科技创始人、香港中文大学教授汤晓鸥在睡梦中逝世,享年55岁。汤晓鸥是中国计算机视觉领域的开拓者,他毕业于中国科学技术大学... AI工具箱3年前
中国计算机视觉领军者、商汤创始人汤晓鸥不幸离世 中国计算机视觉领域巨匠商汤创始人汤晓鸥不幸离世原文标题:哀悼 !中国计算机视觉领军者、商汤创始人汤晓鸥去世关键词:商汤,人工智能,中文,实验室,视觉文献来源:AI科技评论文本字数:3041字文本摘要:王悦 撰写 陈彩娴 编辑整理。12 月 16 日中午,AI科技评论获悉:中国人工智能领域重要人物、商... AI工具箱3年前
斯坦福华人提出LLM生成无限延伸的3D动画生成框架,一句话一幅图创造无限3D世界 本文介绍了斯坦福的华人研究人员提出的全新视频生成框架WonderJourney,能够通过一句话或者一张图自动生成一系列3D场景的连续画面。该框架的独特之处在于可以创造出无限延伸的3D世界,让人工智能技术和艺术结合产生出惊人的效果。通过这项技术,只需一张图像,就能够生成逼真的3D场景,展现出令人惊叹的... AI工具箱3年前
GPT-4V作为机器人大脑,你可能都不需要AI进行规划 本文介绍了清华大学交叉信息研究院的研究者提出的「ViLa」(全称Robotic Vision-Language Planning)算法,该算法能在复杂环境中控制机器人,实现任务规划。文章指出,虽然GPT-4V已经能够设计网站代码并控制浏览器等虚拟数字世界应用,但如果将其应用于控制机器人,可能会产生一... AI工具箱3年前
厦大等发布「视觉感知基础模型」APE,涵盖160个SOTA参数 本文讨论了由厦门大学等机构提出的新视觉感知基础模型APE,该模型仅需一个模型和一组参数,即可在160个测试集上达到当前SOTA水平或具有极高竞争力。该模型不仅训练和推理代码开源,而且无需微调即可立即使用。研究人员从任务泛化、数据多样性和适用性三个方面构建了APE的重要能力。详细内容可参阅原文:一套参... AI工具箱3年前
梅卡曼德联合创始人付翱:AI与3D技术共同引领智能制造新时代|甲子引力 本文来源于甲子光年,是关于梅卡曼德联合创始人付翱在“制造新纪元:智能制造、机器人、商业航天专场”上所做的演讲的报道。付翱认为,3D技术与人工智能的结合已经实现了从0到1的突破,接下来的挑战将是通过完善自动化流程,将这种结合应用于不同行业、不同领域并实现全球化应用,从而实现从1到100的跨越。付翱主张... AI工具箱3年前
首个全方位精通3D任务的拟人智能体:具备感知、推理、规划和行动能力 本文来源于机器之心,介绍了北京通用人工智能研究院联合北京大学、梅隆大学和清华大学提出的首个三维世界中的具身多任务多模态的通才智能体LEO。这一智能体旨在实现对三维世界的理解和交互,弥补现有模型在三维世界方面的不足。详细内容请见原文:首个精通3D任务的具身通才智能体:感知、推理、规划、行动统统拿下。如... AI工具箱3年前
字节月底推出生成式AI开发平台;马斯克旗下Grok将在一周左右向X订阅用户开放;王慧文投资大型AI创企丨AIGC大事日报 本文介绍了一系列关于人工智能产业的最新动态,包括字节跳动推出AI机器人开发平台、马斯克的Grok即将向X订阅用户开放、王慧文入股大型AI创企等。文章总字数达到9490字,内容来源于AI导航。其中重要的信息包括谷歌Gemini推迟发布、微软Copilot全面上市、OpenAI GPT商店推迟上线等。此... AI工具箱3年前
资深学者共同研发的纯CV大模型在UC伯克利呈现通用视觉推理突破 新闻来自机器之心,题为“通用视觉推理显现,UC伯克利炼出单一纯CV大模型,三位资深学者参与”。文章介绍了UC伯克利和约翰霍普金斯大学的研究者最新论文中探讨的内容,展示了大型视觉模型(LVM)在多种CV任务中的应用潜力。最近,大型语言模型(LLM)如GPT和LLaMA备受关注,而构建大型视觉模型(LV... AI工具箱3年前
何恺明、谢赛宁回归学界,R-CNN创始人Ross Girshick离开,Meta CV迎来了多少大神 最新动态:AIGC原标题:R-CNN创始人Ross Girshick离职,何恺明、谢赛宁回归学术界,Meta CV涌现多位顶尖科学家关键词:科学家、视觉、专家、计算机、学术文章来源:机器之心字数:本文共5115字简要内容:机器之心的报道编辑杜伟和陈萍指出,Yann LeCun表示:“尽管人才离开FA... AI工具箱3年前
哈工深发布多模态大模型「九天」,性能直升5%,横扫13个视觉语言任务! <img src=""> 阅读AIGC动态的最新消息 近日,哈工深发布了名为「九天」的多模态大模型,在13个视觉语言任务上取得令人瞩目的进展,性能提升了5%。这一成果融合了细粒度空间感知和高层语义视觉知识,为多模态大语言模型领域带来了新的突破。 该研究由哈尔滨工业大学... AI工具箱3年前
北大新发布的多模态大模型:可在混合数据集上直接应用于图像和视频任务训练 欢迎阅读AIGC动态近期,北大发布了最新的多模态大模型开源消息,该模型可在混合数据集上进行训练,无需修改即可用于图像和视频任务。关键词:视觉、视频、模型、图片、方法文章来源:量子位字数:5682字文章摘要:北京大学和中山大学联合团队最近提出一种构建统一的图片和视频表征框架的方法。他们通过这一框架,大... AI工具箱3年前
北大仅用3天训练130亿参数的Chat-UniVi统一图片和视频理解大模型 最新动向的介绍原文题目:北大提出Chat-UniVi:在3天内训练130亿大模型实现图片和视频统一理解关键词:视觉,模型,视频,图片,表征文章来源:机器之心原文字数:5352字内容摘要:在最新的机器之心专栏中,北京大学及中山大学的研究团队提出了一种名为Chat-UniVi的统一视觉语言大模型。该模型... AI工具箱3年前
沈向洋展示IDEA研究院新模型:开箱即用,无需训练或微调 本文来自量子位,介绍了IDEA研究院最新研究成果——基于视觉提示(Visual Prompt)模型T-Rex。该模型新的目标检测范式可实现即开即用,只需几个简单步骤即可完成。相较于以往基于文本提示的范式,这种以图换图的模式能更轻松地解决复杂、罕见场景。文章还提到了大会中其他有价值的内容,如Think... AI工具箱3年前
IDEA 研究院院长沈向洋宣布重磅研究成果发布 AIGC动态欢迎阅读 近日,AI科技评论发布了一篇名为“懂语言者得天下,IDEA 研究院沈向洋宣布重磅研产结晶”的文章。文章介绍了IDEA研究院创院理事长、美国国家工程院外籍院士沈向洋在2023 IDEA大会上的重要讲话,以及该研究院在AI领域所取得的成果和市场化进展。会议上,众多科学家、企业家和创... AI工具箱3年前
GPT-4V新王加冕,斩获视觉问答冠军 AIGC动态欢迎阅读 近日,夕小瑶科技说发布了一篇题为“新王加冕,GPT-4V 屠榜视觉问答”的文章。文章指出,多模态大型模型(MLLM)在视觉问答领域展现出卓越能力,尤其是针对知识密集型VQA任务,需要结合知识库深入理解视觉信息。对于近期提出的GPT-4V,文章从理解、推理和解释等方面进行了综合评... AI工具箱3年前
北大发布全新Video-LLaVA视觉语言大模型,视频问答技术达到新高度 本文报道的是来自北京大学等机构研究者提出的一种新型全新视觉语言大模型——Video-LLaVA。该模型使得LLM能够同时接收图片和视频作为输入,并在下游任务中表现出色,在图片和视频13个基准上达到先进性能。这一研究结果表明,统一LLM的输入可以提升其视觉理解能力。与传统的视觉语言大模型不同,Vide... AI工具箱3年前
北京大学发布新一代模型,领跑搞笑抖音视频AI识别笑点技术,已开源 <img src=""> AIGC动态欢迎您的阅读 原文标题:北大视频大模型新的SOTA,搞笑抖音视频AI秒懂笑点|开源 关键词:报告、视觉、视频、编码器、表示 文章来源:量子位 内容字数:3357字 文章摘要:本文介绍了北大团队开发的视觉语言大模型Video-LLa... AI工具箱3年前
抢秒必胜:人工智能引领战场速度较量! 《AIGC动态》热点分享 原标题:人工智能在战争中的加速应用! 关键词:报告、数据、模型、指挥所、视觉 文章来源:《人工智能学家》 字数统计:11132字 内容摘要:随着人工智能技术的迅猛发展,美国国防规划者越来越重视人工智能在指挥和控制领域所展现出的超乎寻常的能力。重要的规划、设计和预算编制工作已... AI工具箱3年前
用户疑似发现OpenAI Bug,有机会免费体验GPT4 <img src=""> 欢迎阅读AIGC动态 原文标题:OpenAI出现Bug,用户可免费转至GPT4 关键词:自然语言处理,程序员,计算机视觉,功能 文章来源:JioNLP 文章字数:263字 内容摘要:本文围绕功能介绍AI、自然语言处理、计算机视觉、数据挖掘、数据分析、C... AI工具箱3年前
微软利用GPT-4V将视频转化为文字,让盲人也能轻松理解电影内容,1小时即可完成 欢迎阅读AIGC动态这篇文章原标题为:微软利用GPT-4V解读视频,不仅可以理解电影内容还可为盲人朗读,处理一小时并非难事。文章涉及关键词:视频、研究者、音频、片段、视觉。文章来源于机器之心。文章字数为7381字。文章摘要:机器之心的编辑Panda和陈萍报道,语言能力已经相当成熟的大规模模型正在进军... AI工具箱3年前
快手推出基于 LaVIT 模型的视觉分词器,实现图文信息统一处理效果 欢迎阅读AIGC动态 本文原标题为:“视觉分词器统一图文信息,快手提出基座模型 LaVIT 刷榜多模态任务” 关键词:快手,图像,视觉,文本,分词 文章来源:夕小瑶科技说 内容字数:8523字 内容摘要:夕小瑶科技说的原创文章作者探讨了一种想法,即通过输入少量文字或图片就能够快速搜索到最相关的短视频... AI工具箱3年前
Octopus:基于视觉的AI模型称霸GTA五星玩家 欢迎阅读AIGC动态原文标题:利用视觉技术打造GTA五星级玩家:Octopus开发进展解读关键词:任务、模型、研究人员、研究报告、视觉技术文献来源:机器之心文章长度:10944字文章摘要:电子游戏如今已成为现实世界的模拟舞台,尤其以《侠盗猎车手》(GTA)为代表。在GTA的虚拟世界里,玩家可以身临其... AI工具箱3年前
南洋理工大学、清华大学发布视觉可编程智能体Octopus:打游戏、做家务全能干 AIGC动态欢迎阅读 原文题目:大型模型勇闯洛圣都,获封为“GTA五星好市民”!南洋理工大学、清华大学等发布视觉可编程智能体Octopus:擅长玩游戏、做家务等多项任务 关键词:任务、模型、研究人员、报告、视觉 文章来源:新智元 文章字数:16924字 内容摘要:新智元报道编辑:LRS 非常兴奋【新... AI工具箱3年前
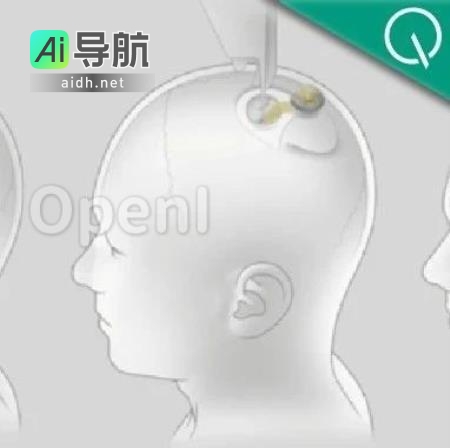
特斯拉首席执行官马斯克发布最新脑机芯片,可帮助失明人群“看见” 欢迎阅读AIGC动态 原标题:马斯克最新研发脑机专用芯片,助失明人群“重见光明” 关键词:芯片、网友、量子、人工智能、视觉 文献来源:量子位 字数统计:2245字 内容摘要:最新消息显示,马斯克旗下Neuralink正在研发一款新型芯片,预计“几年内”发布,旨在通过脑机接口解决失明问题。近期,一位网... AI工具箱3年前
微软 MM-VID 让 GPT-4V 实现追剧、刷抖音、打游戏、玩手机的全新可能性! AIGC动态欢迎阅读 原标题:GPT-4V 也懂追剧、刷抖音、玩游戏、使用手机?微软 MM-VID 发挥出 GPT-4V 的潜力 关键词:视频、脚本、内容、能力、视觉 文章来源:夕小瑶科技说 字数:9596字 摘要:夕小瑶科技说原创作者 | 付奶茶、ZenMooreGPT-4V 在多模态图像理解能力... AI工具箱3年前
OpenAI 首届开发者大会:打造更便宜、更强大的模型 AIGC动态欢迎各位读者。本文转载自AI范儿,原题为《OpenAI将在首届开发者大会上让模型更便宜、更强大》。OpenAI在首次开发者大会上宣布了产品升级,使其AI模型更具性价比、功能更强大。这些升级的目标是鼓励企业利用OpenAI技术构建AI机器人和自主代理,以执行无需人类干预的任务。OpenAI... AI工具箱3年前
何恺明:科研先锋,我问你答完整版曝光 人工智能与大数据的最新动态原标题:何恺明做科研也感慨!最新问答完整版详细解析关键词:模型、数据、问题、神经网络、视觉文章来源:量子位内容字数:11384字概要:AI领域的泰斗何恺明最近的一席谈话引起轰动。他表示:科研中95%的时间是令人沮丧的。这句话让人颇有感触。何恺明最近在香港中文大学的一次讲座中... AI工具箱3年前
GPT-4V基准测试错误率高达90%:红绿灯认错、勾股定理也不会 文章介绍了关于GPT-4V在最新基准测试中表现不佳的情况。文章指出,尽管GPT-4被赞誉有加,但作为具备视觉能力的GPT-4版本——GPT-4V,在测试中出现了高达90%的错误率。其中,文章举例说明了GPT-4V在识别红绿灯和应用勾股定理等简单问题时出现的困难,甚至对直角三角形和钝角三角形的计算也出... AI工具箱3年前
中科大等团队提出「Woodpecker」幻觉修正架构,成功降低30%多模态大模型幻觉误差 AIGC动态欢迎阅读近日,中科大等机构的研究人员提出了一项重要的研究成果,即首个多模态修正架构「Woodpecker」,旨在解决MLLM输出幻觉的问题。在多模态大语言模型(MLLMs)中,视觉幻觉是一个常见问题,即模型生成的描述与图片内容不一致。简单来说,就是模型的输出与实际图片不符。这一研究极大地... AI工具箱3年前
清华大学光电计算实现新突破:芯片性能大幅提升,研究成果发表在《自然》杂志 欢迎阅读AIGC动态 原文标题:清华大学在光电计算领域取得新突破:芯片性能提升万倍,研究登上《Nature》 关键词:芯片、架构、清华大学、系统、视觉 文章来源:机器之心 文字长度:4490字 内容摘要:清华大学团队在超高性能计算芯片领域取得重要突破,相关研究成果发表在《Nature》杂志上。随着各... AI工具箱3年前
GPT-4V 连北京烤鸭都不认识?别再盲目吹捧了! 近期,有文章指出即使是被大家普遍看好的具备视觉能力的 GPT-4 版本——GPT-4V,也存在识别问题。据报道,GPT-4V 甚至无法区分图片上的“北京烤鸭”和“广西烤鸭”,这一情况着实让人大跌眼镜。文章通过对 GPT-4V 和 LLaVa-1.5 的实验展示,两者在面对“广西烤鸭”的图片时,均判断... AI工具箱3年前
基于视觉大模型,虹软引领商拍市场的革新|甲子光年 <img src="" />AIGC动态原文标题:利用视觉大模型,虹软引发商拍市场一场豹变|甲子光年关键词:模型、视觉、报告、智能、科技文章来源:甲子光年字数:7217字内容摘要:虹软PhotoStudio® AI推出“卖家秀”。作者:陈杨,编辑:王博。今年“双11”大促即将到... AI工具箱3年前
秋季新品发布:电商卖家秀一键生成神器来袭,虹软商拍玩法大改革! <img src=""> 关于AIGC的最新动态 原标题: 今秋首个AIGC爆款应用现已发布?电商卖家秀一键生成,虹软改变商拍玩法 关键词:模型,模特,产品,技术,视觉 文章来源:AI导航 字数统计:本文共7897字 内容摘要:揭开AIGC商业拍摄图工厂的神秘面纱!这... AI工具箱3年前
NeurIPS 2023研究:多模态查询方法让大模型看图比打字管用,准确率提升7.8% 量子位动态介绍 本文转载自沁园夏量子位,公众号 QbitAI。大型AI模型的图像识别能力已经非常强大,但为什么它们仍然经常混淆物体?比如,将长得不太像的蝙蝠和拍子混淆,或者无法识别数据集中的一些稀有鱼类……这是因为当我们让大型模型“寻找事物”时,通常输入的是文本。如果描述模糊或者太专业化,比如“ba... AI工具箱3年前
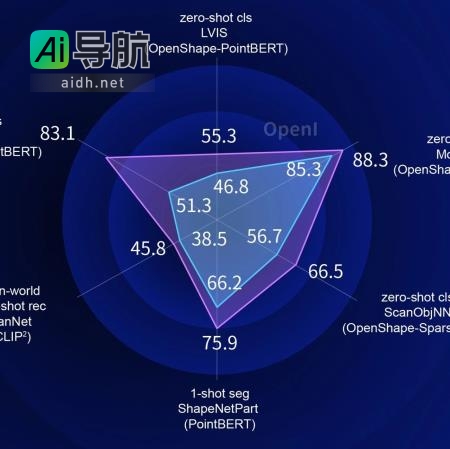
智源和清北联手,发布10亿参数Uni3D视觉大模型,助你从「最强2D」升级到「最强3D」 本文介绍了智源、清华和北大联合发布的10亿参数的3D视觉通用模型Uni3D,该模型在主流3D视觉能力上表现出色。文章指出计算机视觉是人工智能的眼睛,三维视觉的研究使机器具备了探知真实空间纵深与距离的能力。发展三维视觉模型对于让机器在复杂场景中更智能地路径规划和与周边精准交互具有重要意义。近日,智源研... AI工具箱3年前
Meta最新研究揭示:AI读脑成真,仅延迟0.25秒!LeCun点赞MEG实时解码大脑图像 AI全球咨询中心最新动态 原标题:人工智能技术实现读脑梦想,仅延迟0.25秒!Meta发布关键性新研究:利用MEG技术实时解码大脑图像,引起深远影响 关键词:图像、大脑、视觉、模型、作者 文献来源:新智元 文章内容长度:8303字 文章摘要:新智元报道编辑:润 贝果【新智元导读】Meta公司取得了一... AI工具箱3年前
华人团队打造的超热门Mini GPT-4在视觉能力上大幅提升,GitHub星数达两万 <img src=""> AIGC动态欢迎阅读 原标题:超火迷你GPT-4视觉能力暴涨,GitHub两万星,华人团队出品 关键字:视觉,模型,任务,指令,量子 文章来源:量子位 内容字数:2492字 内容摘要:最新报道指出,GPT-4V虽然在目标检测上表现出色,但仍有... AI工具箱3年前