GPT-4科研成果发表在《自然》杂志!布洛芬配方简单操作,实现诺奖得主提出的复杂反应 人工智能化学家Coscientist登上Nature 原标题:GPT-4搞科研登Nature!布洛芬配方轻松拿捏,诺奖得主提出的复杂反应也能完成关键字:模块,反应,化学家,指令,机器人文章来源:量子位内容字数:4547字 内容摘要: 最近一款名为Coscientist的 AI 系统成功登上了《Nat... AI工具箱3年前
笑话无法讲好的大型AI模型,已经晋升为梗王!探讨经典梗图,停不下来 <img src=""> 欢迎阅读AIGC动态 原标题:超有梗!笑话都讲不好的大型模型,已经发展成梗王!解读经典梗图让人停不下来。关键字:数据、指令、任务、能力、创造性。文章来源:夕小瑶科技说。内容字数:4870字。 内容摘要: 夕小瑶科技说的原创作者:付奶茶,大家有... AI工具箱3年前
北京大学发布LLMs数据管理全流程综述:预训练与微调 近日,北京大学的学者发布了一篇关于大型语言模型(LLMs)训练数据管理全流程的综述文章。该文章探讨了LLMs在预训练和有监督微调两个阶段的数据管理情况,包括数据规模、数据质量、领域组成以及数据管理系统等方面的研究内容。在这篇综述中,作者详细总结了数据管理对于LLMs性能提升的重要性,强调了数据规模与... AI工具箱3年前
清华大学发布ViLa研究:GPT-4V在机器人视觉规划中的潜力揭秘 对于机器人系统来说,底层指令可能是精确的关节或轮速控制。相比之下,高级语言指令可能是描述一个任务或目标,比如“将蓝色的盘子放在桌子上”。这种高级语言指令更接近人类日常语言,易于理解,而不需要详细规定每个具体的动作。因此,使用高级语言指令有助于提高系统的可理解性和用户友好性。当前,关于视觉语言模型(V... AI工具箱3年前
《零一万物Yi大模型新评测:英语能力仅次于GPT-4》 欢迎阅读AIGC动态 原标题:零一万物 Yi 大模型最新评测,英语能力仅次于 GPT-4 关键词:模型、能力、数据、指令、方面 本文转载自AI科技评论 字数:4230字 摘要:全球大模型竞技呈现激烈局面,零一万物发布性能出色的Yi-34B基座模型后,Yi-34B-Chat微调模型于11月24日开源,... AI工具箱3年前
微软发布Orca2,助您掌握小规模大语言模型的推理技巧! 这篇文章介绍了微软最新发布的小型大语言模型Orca2,以及如何提升这种小型模型的推理能力。文章指出,尽管通常认为语言模型的体量与推理能力成正相关,但小型模型也能展现出色的推理性能。通过解释跟踪等方法训练模型,Orca2在BigBench Hard和AGIEval基准测试中表现出色。研究团队在Orca... AI工具箱3年前
GPT-4再升级!「角色调节」方法让大型模型轻松逃逸,成功率飙升40%,成本不到14元,马库斯大加赞扬 最近有一篇关于GPT-4和角色调节的文章引起了广泛关注,文章称研究人员开发了一种叫做「角色调节」的新型自动化越狱方法。这种方法能让大模型成功越狱,并且成本低廉,成功率还暴涨了40%。具体内容请参见原文链接。 文章来源于新智元,主要涉及到角色、模型、政策、指令和研究人员等关键词。这一研究的重要性在于,... AI工具箱3年前
ChatGPT发布了,开源大模型已经迎头赶上了吗? 该篇文章讨论了开源大模型的现状和潜力,重点关注了ChatGPT的发布与影响。文章指出ChatGPT开源以前闭源模型所存在的一系列问题,如技术细节保密、API成本高昂、数据所有权和隐私问题等。为此,开源社区备受期待,尽管初始阶段的基础模型性能或许无法与ChatGPT相媲美,但仍有望不断提升。最后,文章... AI工具箱3年前
LeCun挑战LLM:大模型「涌现」离不开上下文学习 在最近的一篇关于大语言模型的文章中,LeCun引起了不小的争议。该文章讨论了LLM的规划推理能力以及涌现能力的主要来源。作者认为,LLM本身并不具备规划推理能力,而涌现出来的各种能力主要是源自上下文学习。这引发了关于大语言模型是否真的会推理的讨论。 在LeCun转发的两篇长文中,他集中探讨了LLM的... AI工具箱3年前
深度催眠引导LLM「越狱」:香港浸会大学首次探索高度可信大语言模型 <img src=""> 阅读AIGC动态欢迎 原标题:香港浸会大学初探可信大语言模型:用深度催眠诱导LLM “越狱” 关键词:指令,模型,嵌套,诱导,场景 文章来源:机器之心 内容字数:9148字 内容摘要:大语言模型(LLM)在各个领域取得了巨大成功,但容易受到某... AI工具箱3年前
谷歌Bard自然语言提示注入漏洞,可能导致数据泄露 本文来自机器之心的报道,标题为“谷歌Bard‘破防’,用自然语言,提示注入引起数据泄漏风险”。文章介绍了一种名为提示注入(Prompt Injection)的黑客技术,黑客可以通过该技术利用自然语言人工智能系统,特别是大型语言模型,来引发数据泄漏风险。这种攻击技术利用模型生成文本时对提示词的依赖,通... AI工具箱3年前
《医学领域大型语言模型研究进展与挑战:以牛津等研究综述为例》 本文介绍了医学中大型语言模型(LLMs)的进展、应用与挑战。LLMs如ChatGPT因其强大的人类语言理解和生成能力而备受关注,将其应用于医学领域,有望成为人工智能和临床医学的重要研究方向。本文提供了关于医学LLMs的综述,包括构建医学LLMs、医学LLMs的表现等方面,并探讨了当前面临的挑战。如果... AI工具箱3年前
Altman亲自打造Grok再现,背叛马斯克!定制GPT正式推出,第三方市场全面上线 最近,Altman在开发者大会上推出了新的产品更新,让所有PLUS用户都能使用。这一举动引起了很多讨论,有人甚至花了整个下午的时间去体验这些更新。在这之前,OpenAI的ChatGPT出现了宕机,但随后正式开放了新功能。此外,Altman还复刻了一个名为「Grok」的产品,似乎在向马斯克发出挑衅。 ... AI工具箱3年前
NYU最新研究成果:利用组合元学习框架实现类人系统的泛化性登上Nature 欢迎阅读AIGC动态原标题:NYU最新研究成果登上Nature:通过组合元学习框架完全实现类人系统的泛化能力关键词:任务、神经网络、模型、人类、指令文章来源:大数据文摘内容字数:6362字内容摘要:大数据文摘得到授权转载自将门创投,作者为seven_。上世纪80年代,认知科学研究者Jerry Fod... AI工具箱3年前
北大智能团队提出需求驱动导航,让机器人更高效满足人类需求 本文是关于北大具身智能团队提出需求驱动导航,以对齐人类需求,从而使机器人更高效的文章。机器之心编辑部想象机器人能够理解用户需求并努力满足这一美好愿景。在现实环境中,用户通常需要给机器人精确的指令才能获取期望的结果。然而,在某些情况下,需要的物品可能并不存在当前环境中,这就会导致机器人无法找到。但是,... AI工具箱3年前
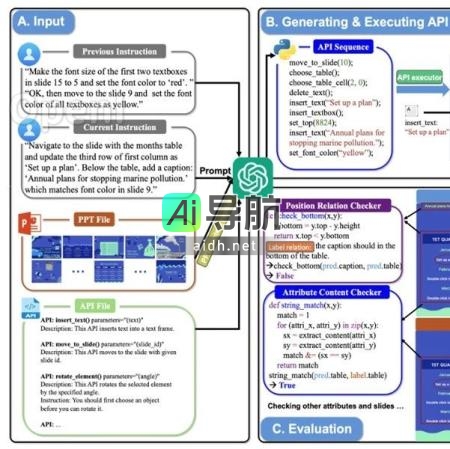
北大等提出首个「多轮、多模态」PPT任务完成基准PPTC,GPT-4正确率仅为6% AIGC动态欢迎阅读 原文标题:GPT-4完成正确率仅6%!北大等提出首个「多轮、多模态」PPT任务完成基准PPTC 关键词:模型、轮次、指令、任务、语言 文章来源:新智元 内容字数:9968字 内容摘要:针对LLM在复杂多模态环境中利用复杂工具完成多轮、多模态指令的评估空白,研究人员引入了Powe... AI工具箱3年前
北大研究取得新突破:无需训练,具身智能机器人可听指令灵活走位 <img src=""> AIGC动态欢迎阅读 近日,北大前沿计算研究中心的董豪团队取得了具身智能领域的新成果,该成果无需额外建图和训练,只需简单说出导航指令,即可让机器人灵活移动。这一突破意味着机器人可以根据语音指令执行复杂的动作,如跨过房间,穿过厨房旁的餐具,并站... AI工具箱3年前
港大发布GraphGPT:微调参数比通用GPT模型1/50,准确率提升10倍!LLM也能理解图结构,无需长token 图神经网络(Graph Neural Networks)已成为分析和学习图结构数据的重要框架,推动了多个领域的进步,如社交网络分析、推荐系统和生物网络分析等。最新的研究表明,利用GraphGPT框架将图结构模型和大语言模型进行参数对齐,通过双阶段图指令微调提高模型对图结构的理解能力和适应性,并整合C... AI工具箱3年前
北理工发布大规模MindLLM模型:小范围模型挑战巨人,揭示巨大潜力 AIGC动态欢迎阅读 原标题:小模型如何比肩大模型,北京理工大学发布明德大模型MindLLM,小模型潜力巨大。 关键字:模型,数据,能力,指令,双语。 文章来源:机器之心。 内容字数:18434字。 内容摘要:北京理工大学发布了明德大模型—MindLLM,这是一种双语轻量级语言模型。大型语言模型 (... AI工具箱3年前
港科大&华为诺亚方舟实验室揭示:喂食“有毒”数据后,大型模型表现更加出色 <img src="">欢迎阅读AIGC动态本文转载自量子位,原标题为“吃‘有毒’数据,大模型反而更听话了!来自香港科技大学和华为诺亚方舟实验室的研究。”研究人员发现,给大型模型喂入一定量的错误文本,然后让模型分析和反思错误的原因,可以帮助模型真正理解错误之处,从而避... AI工具箱3年前
清华研究:Llama2挑战GPT-4,大幅提升大模型通用智能能力 AIGC动态欢迎阅读 原标题:清华最新研究:让Llama2直逼GPT-4,大幅提升大模型的通用智能能力! 关键词:智能、任务、模型、指令、轨迹 文章来源:大数据文摘 内容字数:14184字 内容摘要:大数据文摘授权转载自夕小瑶科技说作者智商掉了一地、ZenMoore智能体是一种能够感知环境、做出决策... AI工具箱3年前
LLM一句话即刻生成3D世界,未公开代码已获141颗星!或将引领3D建模行业变革 AIGC动态欢迎阅读 近日,由澳大利亚国立大学、牛津大学和智源公司的研究人员提出了一个基于LLM技术的智能体框架,通过简单的文字提示即可生成复杂的3D场景。这一新技术或许将在3D建模行业引起重大变革。 关键词包括研究人员、建模、场景、指令和函数。 文章来源:新智元 全文共8077字,编辑:润 好困 ... AI工具箱3年前
5个字符的新绘图语言在ChatGPT中流行起来 本文来源于“量子位”公众号,介绍了一种新的绘图语言CFR[],仅需五个字符就能完成像素画的绘制,支持8种颜色,画幅可达256*256。CFR[]是免费开源的,在线体验。虽然只有5个符号,但它的图像绘制并不简单。作者展示了CFR[]的一个DEMO。详情请查看原文:仅5个字符的新绘图语言火了,ChatG... AI工具箱3年前
华人团队打造的超热门Mini GPT-4在视觉能力上大幅提升,GitHub星数达两万 <img src=""> AIGC动态欢迎阅读 原标题:超火迷你GPT-4视觉能力暴涨,GitHub两万星,华人团队出品 关键字:视觉,模型,任务,指令,量子 文章来源:量子位 内容字数:2492字 内容摘要:最新报道指出,GPT-4V虽然在目标检测上表现出色,但仍有... AI工具箱3年前
ChatGPT安全性受到微调攻击风险:普林斯顿、斯坦福研究发布LLM预警 本文介绍了微调语言模型(LLM)可能存在的安全风险,指出微调过程中使用良性数据和角色扮演等方式可能破坏模型的性能对齐。虽然预训练语言模型在某些情况下表现出色,但在实际应用中,通常需要对其进行微调以适应特定任务。然而,微调后的模型安全性、对齐性能是否受影响,以及在面向用户时可能产生的风险等问题尚需进一... AI工具箱3年前
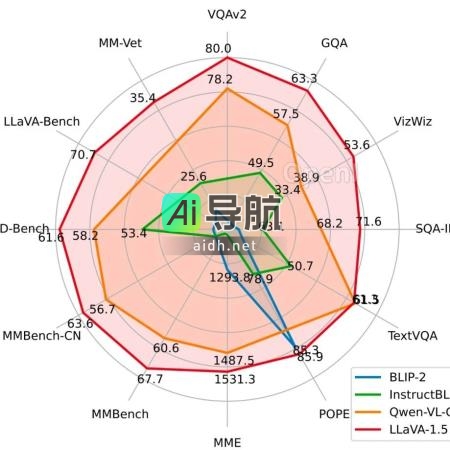
LLaVA-1.5在一天内使用1.2M数据、8个A100训练,刷新11项基准SOTA,挑战GPT-4V 欢迎阅读AIGC动态 原文标题:GPT-4V媲美,仅用1.2M数据和8个A100,在一天内完成训练,LLaVA-1.5超越11个SOTA基准 关键词:数据、格式、模型、能力、指令 文章来源:机器之心 文字篇幅:4509字 内容摘要:机器之心报道由编辑蛋酱和小舟发布,多模态大型模型的时代正式来临。不久... AI工具箱3年前
成为LLM专家的不二法门:认识RLHF及其替代技术 本文来自机器之心,标题为"AIGC动态欢迎阅读",原文题为"LLM成功不可或缺的基石:RLHF及其替代技术"。文章长度14445字,主要讨论了训练大型模型常用的RLHF技术,对其工作过程进行了解读,并总结了一些替代方法。在讨论LLM时,提到了“使用人类反馈的强... AI工具箱3年前
AlpacaEval上首个超越GPT-4的模型已现身! 欢迎阅读AIGC动态原文标题:首个在AlpacaEval超越GPT-4的模型现身!关键词:模型、AlpacaEval、GPT-4、Xwin-LM、AI文献来源:夕小瑶科技说字数统计:6030字文章摘要:夕小瑶科技说分享新智元的消息,首个在AlpacaEval上超越GPT-4的模型,近日现身!今年6月... AI工具箱3年前
Xwin-LM 700亿参数模型在斯坦福AlpacaEval比赛中击败GPT-4,13B模型轻松战胜ChatGPT 最近,一篇关于Xwin-LM模型在斯坦福AlpacaEval上的表现超越GPT-4的文章引起了广泛关注。据报道,Xwin-LM是一款参数达到700亿的模型,在AlpacaEval榜单上取得了突出的成绩,成功赶超了一直稳居榜首的GPT-4。这个新的成绩让人们开始重新审视这个领域的竞争格局。 Xwin-... AI工具箱3年前
深呼吸:谷歌DeepMind利用大型语言模型生成Prompt,AI感知AI更胜一筹 近日,新智元报道了谷歌DeepMind提出的新优化框架OPRO,该框架可以通过自然语言描述来引导大型语言模型逐步改进解决方案,实现各种优化任务。具体来说,DeepMind利用大型语言模型生成Prompt提示词,如在命令中加入“深呼吸”,就可以使模型在某项任务中表现更出色。通过这种方式,模型在GSM8... AI工具箱3年前
NUS华人团队发布NExT-GPT:AGI水平的多模态大模型现已实现 <img src=""> 欢迎阅读AIGC动态 本文来源于机器之心,介绍了新加坡国立大学华人团队开源的NExT-GPT模型,这是一种支持任意模态输入和输出的多模态大模型。该模型受到了AI社区的热烈关注,尤其在ChatGPT问世后,大语言模型的浪潮愈演愈烈。随着Flan... AI工具箱3年前
Midjourney实操学习手册:奶奶必备的常用命令汇总,学会收藏! <img src=""> AIGC动态欢迎阅读 本文原标题为:奶奶看了都会的Midjourney实操学习手册,整理了常用命令汇总,建议收藏!如果你对图像、指令、模式、命令和算法感兴趣,不妨继续阅读。 文章来源:元动乾坤 内容字数:11392字 近期,备受关注的智能绘画... AI工具箱3年前
AI大牛揭秘:RLHF何以成为LLM训练的关键?深度解析Llama 2反馈机制升级 本文是新智元报道的一篇关于RLHF(基于人类反馈的强化学习)在AI技术中的应用的文章。文章提到了RLHF作为一种训练方式在当前AI领域的重要性以及未来发展方向的讨论。除此之外,还介绍了一些新的替代方案,并详细解释了Llama 2反馈机制的升级内容。结合了ChatGPT等大型语言模型的应用,文章探讨了... AI工具箱3年前
新加坡华人团队发布开源多模态大模型「大一统」,助力无限接近AGI! AIGC动态欢迎阅读本文报道了新加坡华人团队开源的全能「大一统」多模态大模型,该模型支持任意模态输入和输出,引起了AI社区的热议。在各类开源LLM问世后,研究人员为了更好地模拟现实世界,将大模型拓展到了处理语言之外的多模态领域,如支持图像的MiniGPT-4、BLIP-2和Fla…原文链接:点击查看... AI工具箱3年前
用四步轻松构建个人Agent!达摩院最新开源框架,小白也能上手 在AIGC动态中阅读欢迎原题目:仅需四个步骤即可构建个人Agent!达摩院最新开源框架适合新手关键词:工具、模型、指令、模块、框架文章来源:量子位字数统计:3361字内容摘要:由李晨亮投稿于量子位| 公众号 QbitAI现在,即使是初学者也可以建立自己的智能体!达摩院最新推出的Agent框架Mode... AI工具箱3年前
使用AI神器ChatGPT的90%以上用户未掌握的实操技巧,值得藏起来的学习手册 本文介绍了AI技术ChatGPT的使用手册。自2022年11月30日推出以来,在国内受到广泛关注。文章强调人类仍然比AI更强大,ChatGPT的逻辑简单,交互体验符合人性,只需通过对话即可使用。然而,并非每个人都能充分利用ChatGPT。作者承诺通过本文教会读者如何掌握ChatGPT的使用方法。如需... AI工具箱3年前
探索微软人工智能助手Microsoft 365 Copilot的强大功能! AIGC动态欢迎阅读 原文标题:微软的人工智能Microsoft 365 Copilot究竟有何强大之处?带您一探究竟! 关键词:数据、工作、时间、电子邮件、指令 文章来源:元动乾坤 内容字数:2287字 内容摘要:在日常工作中,我们将80%的时间用于基础和琐碎工作,只有20%专注于核心工作。随着微... AI工具箱3年前
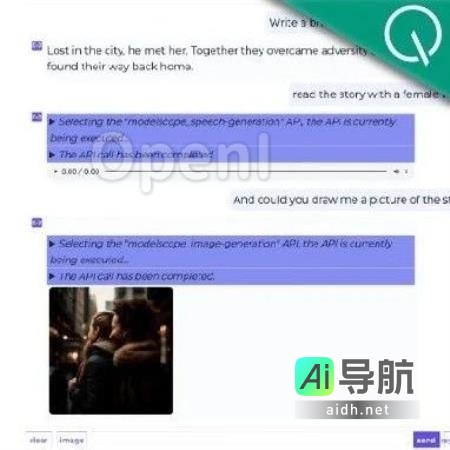
使用ModelScope-Agent 打造个性化智能体,保姆级教程免费送达 本文介绍了一款名为ModelScope-Agent的工具,使得即使是不擅长技术的用户也能够轻松打造专属智能体。该工具在大模型时代中具有重要作用,围绕着大模型的自主智能体被认为是通向通用人工智能(AGI)的关键路径。随着OpenAI提出了增强大模型能力的插件等方法,社区中涌现出了一系列Agent系统,... AI工具箱3年前
英伟达成为GPU霸主的四大成功要素!首席科学家揭秘全球抢购H100背后的秘密 AIGC动态欢迎阅读 原文标题:全球哄抢H100!英伟达成GPU霸主,首席科学家揭秘成功四要素 关键词:表现、成本、指令、数字、规律 文章来源:新智元 内容字数:3856字 内容摘要:本文由新智元编辑桃子 润报道,英伟达首席科学家揭示了英伟达GPU取得成功的四大要素,四项关键数据带来了持续的行业竞争... AI工具箱3年前
DeepMind发现告诉大型模型“深呼吸,一步一步来”为最有效提示 AIGC动态欢迎阅读本文标题为:“告诉大模型「深呼吸,一步一步来」有奇效”,DeepMind发现最有效的提示方法。本文关键词包括:指令、提示、任务、准确率。文章来源:机器之心。本文共4590字,内容摘要如下:本文介绍了一种名为OPRO的简单而有效的方法,该方法利用大型语言模型作为优化器,通过自然语言... AI工具箱3年前