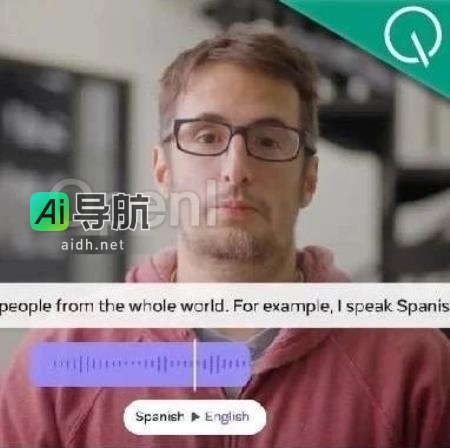
Meta发布了能够模仿语气和语速的大型翻译模型!AI不再冷冰冰了|GitHub 标星破9k AIGC动态欢迎阅读 原标题:Meta翻译大模型可模仿语气语速!AI再也不“莫得感情”了|GitHub 9k标星关键字:模型,语音,语言,文本,水印文章来源:量子位内容字数:4459字 内容摘要: 丰色 发自 凹非寺量子位 | 公众号 QbitAIMeta发布了全新AI翻译大模型,实时语音转换延迟不... AI工具箱3年前
谷歌发布全新视频生成大型语言模型VideoPoet AI时代新动态 原标题:谷歌推出视频生成巨型语言模型VideoPoet关键词:视频、模型、文本、音频、图像文章来源:AI范儿字数:2042字 内容摘要: 请点击上方链接关注我们。谷歌推出了VideoPoet,这是一款生成式人工智能系统,能够通过文本等输入创建和编辑视频。与其他竞争模型不同,Video... AI工具箱3年前
谷歌发布新大语言模型:零样本生成10秒视频达SOTA,网友各路艺术从业者感压力↑↑↑ 最新动态: 近期,谷歌发布了一项引人关注的新技术:一种先进的大型语言模型,能够在零样本情况下生成高质量的10秒视频。这一成果迅速引起了业界的关注和讨论。网友们纷纷表示期待看到这一技术未来的应用,也给了其他相关公司一些压力。 文章概要: 据明敏在凹非寺量子位的报道,谷歌最新推出的大型语言模型Video... AI工具箱3年前
谷歌发布VideoPoet大模型,网友:视频生成无限可能 这篇文章来自机器之心报道,介绍了谷歌推出的视频生成大模型VideoPoet,受到了人们的关注。该模型被认为是一种性技术的零射视频生成工具,能够生成多样化且流畅的视频内容。文章中提到了一些人对于这款大模型的生成长度和性质表示了好奇和期待,有人呼吁谷歌尽快开源VideoPoet。随着生成式人工智能的发展... AI工具箱3年前
谷歌发布全新零样本视频生成模型,效果惊艳超越传统扩散模型? AIGC动态欢迎阅读原标题:谷歌重磅发布零样本视频生成模型!效果惊艳,赶超扩散模型?关键字:视频、模型、文本、图像、语言文章来源:夕小瑶科技说内容字数:1739字夕小瑶科技说原创作者:王二狗今日,谷歌AI发布了最新的视频生成模型VideoPoet。VideoPoet不采用常见的扩散模型架构,实质上是... AI工具箱3年前
AI模型解读脑电波:人类思绪实时投射屏幕|NeurIPS 2023 AIGC动态欢迎阅读 近期举办的NeurIPS会议上,研究人员展示了先进人工智能的一项令人震惊的应用——AI读心术。当前的人工智能已经可以进行绘画、作曲、生成视频、创作小说、扮演主播等工作。然而,在最近的NeurIPS会议上,来自GrapheneX-UTS的研究人员推出了更加惊人的应用——AI读心术... AI工具箱3年前
LLM打破记录,超越Gen-2,创造谷歌10秒视频生成神话 最新的报道显示,谷歌推出了一款新的视频生成模型VideoPoet,引领全球视频生成技术发展。这款模型能够生成10秒超长且连贯的大动作视频,效果远超先前的Gen-2模型。与其他领先模型不同的是,VideoPoet无需特定数据即可生成视频,为业界带来了新的可能性。该模型的发布再次凸显了谷歌在人工智能领域... AI工具箱3年前
OpenAI官方指南:如何玦玩ChatGPT的Prompt功能 最近,OpenAI官方发布了一份提示工程指南,旨在帮助用户更好地利用像ChatGPT、GPT-4这样的大型语言模型(LLM)以获得更优质的输出结果。该指南重点介绍了写作prompt的六个策略,其中包括了写清楚指令、要求专家级别的写作等。写好prompt对于影响模型输出结果至关重要,因为模型无法读取用... AI工具箱3年前
阿里文生视频挑战Gen-2、Pika,1280×720高清画质流畅播放,3500万像素呈现文本与视频绝佳效果 AIGC动态欢迎阅读 近日,阿里巴巴的研究掀起了文生视频领域的新热潮。一项名为I2VGen-XL的文生视频模型展示了惊人的表现,能够以1280×720分辨率高质量、流畅地生成各类视频,包括艺术画作、人物肖像、动物、科幻图等。其中包含了一些示例文本:“一只小猫在花丛中,中国画。”、“一个黄色的机器人。... AI工具箱3年前
谷歌宣布Gemini API开放,ChatGPT Plus订阅重新启动! 最新动态:AIGC 原标题:谷歌宣布启用Gemini API,ChatGPT Plus订阅重新开放 关键词:图像、开发者、文本、功能、谷歌 引用自:夕小瑶科技 文本长度:5149字 内容概要:夕小瑶科技报道,作者王二狗。人工智能领域的动态异常精彩,OpenAI和谷歌再次展开激烈竞争。Sam Altm... AI工具箱3年前
斯坦福华人提出LLM生成无限延伸的3D动画生成框架,一句话一幅图创造无限3D世界 本文介绍了斯坦福的华人研究人员提出的全新视频生成框架WonderJourney,能够通过一句话或者一张图自动生成一系列3D场景的连续画面。该框架的独特之处在于可以创造出无限延伸的3D世界,让人工智能技术和艺术结合产生出惊人的效果。通过这项技术,只需一张图像,就能够生成逼真的3D场景,展现出令人惊叹的... AI工具箱3年前
Imagen 2登场,正面对决DALL·E 3和Midjourney,谷歌文生图巅峰之战! 在新智元报道中,谷歌最新发布的文生图AI模型Imagen 2引起了广泛关注。根据报道,Imagen 2在生成图像的逼真程度方面表现优秀,甚至超越了之前的DALL·E 3和Midjourney。通过输入具体描述,如“一位32岁的年轻女性自然保护主义者,正在丛林中探险。她体格健壮,一头短卷发,面带亲切的... AI工具箱3年前
阿里再次创新:一张人脸一句话就能玩《擦玻璃》,服装背景任意更换! 欢迎阅读AIGC动态原标题:阿里巧妙创新:一张人脸一句话就能跳《擦玻璃》,服装背景自由更换!关键词:视频,阿里,内容,舞蹈,文本文章来源:量子位内容字数:3098字内容摘要:金磊 发自 凹非寺量子位 | 公众号 QbitAI阿里再次带来了一项引人注目的“舞蹈创新”技术,这次只需一张脸部照片和一句话描... AI工具箱3年前
12月11日|AIGC重要事件日报 AIGC动态相关报道原文标题:12.11丨AIGC大事日报关键词:模型、公告、论文、人民网、文本文献来源:AI导航字数统计:7329字摘要内容:12月11日AIGC全球产业要闻包括:1、智谱AI发布文本质量评价模型CritiqueLLM;2、智源研究院发布LM-Cocktail模型治理策略;3、北大... AI工具箱3年前
大模型归因机制揭秘:解决幻觉难题! 欢迎阅读AIGC动态 原标题:详解大模型的归因机制,解决幻觉问题 关键词:报告、模型、答案、文本、问题 文章来源:夕小瑶科技说 字数:8989字 内容摘要:大型语言模型的幻觉问题一直是一个迫切需要解决的挑战。由于这些大型模型训练数据广泛,未经筛选,而且目标仅在于预测下一个单词,没有对生成内容的真实性... AI工具箱3年前
谷歌DeepMind发布Gemini:史上最强最通用大模型,挑战GPT-4! AIGC动态欢迎阅读 原标题:超越GPT-4!谷歌DeepMind重磅发布Gemini,史上最强最通用大模型! 本文来自夕小瑶科技说,全文共计5651字。夕小瑶科技说的原创作者王二狗深夜透露,谷歌DeepMind最新发布的Gemini大模型堪称谷歌史上功能最强大、最通用的多模态模型,在多项领先基准测... AI工具箱3年前
谷歌深夜发布最新强大模型Gemini,性能超越GPT-4,附60页技术报告【突发消息】 AIGC动态欢迎阅读 原标题:谷歌发布最强大模型Gemini,超越GPT-4并附60页技术报告 关键词:报告、模型、基准、任务、文本 文章来源:AI导航 内容字数:7643字 内容摘要:谷歌发布了最新的AI大模型Gemini,在多任务语言理解的测试中首次超越人类专家,取得了30个最优效果,几乎全面超... AI工具箱3年前
CMU提出可追溯溯源的AI文本判别器模型 欢迎阅读AIGC动态 原文标题:追踪溯源?可定位源头模型的AI文本判别器出现了!CMU提出 关键词:文本,任务,报告,模型,作者 文章来源:夕小瑶科技说 字数:7499字 内容摘要:自从去年底ChatGPT发布以来,大型语言模型(LLM)的应用范围越来越广,从写小说、撰写文案和报告,到编写代码,在各... AI工具箱3年前
中国团队发布开源图文数据集ShareGPT4V,多模态性能实现质的飞跃 <img src=""> AIGC动态欢迎阅读 原标题:中国团队开源大规模高质量图文数据集ShareGPT4V,超越同级7B模型,极大提升多模态性能。 关键词:数据、模型、图像、文本、画作。 文章来源:新智元。 内容字数:7209字。 内容摘要:研究人员利用GPT4-... AI工具箱3年前
胡渊鸣新项目Meshy:一分钟内快速生成3D游戏资产 在机器之心网站发表的文章中,介绍了一款名为Meshy的在线生成AI工具,能够在一分钟内生成3D内容(模型),只需要用户提供简单提示。随着3D内容在游戏、电影和XR行业需求不断增长,Meshy的出现填补了市场中对快速、高效生成3D内容的需求。文章还提到,Meshy是一家名为Me…的创业公司所推出的产品... AI工具箱3年前
大型双面人:虚假新闻制造机对抗假新闻鉴别大师 这篇文章讨论了大型语言模型在制造虚假信息方面的潜力。研究团队选取了10种不同的大语言模型,通过使用20种虚假信息叙事来评估它们的性能。这些叙事涵盖了COVID-19、俄乌战争、健康、美国和区域性话题等五个类别。研究结果显示,这些大语言模型能够制造出令人信服的虚假新闻。 原文链接:大模型变身双面人:虚... AI工具箱3年前
提升大模型能力:利用检索增强生成的Python实现指南 本文源自《机器之心》,介绍了如何通过检索增强生成(RAG)让大型语言模型(LLM)更加强大的内容。RAG的概念是利用外部知识源为LLM提供额外信息,使其可以生成更准确、符合上下文的答案,并减少幻觉。文章首先讨论了人们如何有效整合LLM的一般性知识与专有数据,引出了微调和RAG哪个更合适的讨论。随后详... AI工具箱3年前
AIGC:实现前端 Web 开发响应式设计与 Tailwind 配置的完美组合 欢迎阅读AIGC动态 本文原题为:AIGC在前端Web开发中的应用:响应式设计与Tailwind配置的完美搭档。 关键词:简写、文本、版本、比例、提示。 文章来源:AI前线。 文章字数:6031字。 内容概要:作者Mike Solomon,译者核子可乐,策划丁晓昀。响应式网页设计中使用ChatGPT... AI工具箱3年前
浙大等研究提出C-MCR:连接多模态对比表征无需配对数据|NeurIPS 2023 本文介绍了浙江大学等机构研究人员提出的一种名为C-MCR的新型多模态对比表征学习方法,旨在解决多模态学习中依赖配对数据的问题。该方法称为连接多模态对比表示(C-MCR),能够在缺乏配对数据的情况下,高效地训练多模态对比表征。通过将不同模态的输入编码到一个共享的语义空间中,C-MCR连接了不同对比表征... AI工具箱3年前
Meta生成式AI最新进化:视频生成升级至Gen-2,动图表情包个性定制达到新高度 这篇文章介绍了Meta公司最新推出的生成式AI技术,在视频生成领域取得了突破,超越了Gen-2和Pika Labs,能够灵活编辑图像和生成高分辨率视频。该技术包括两项工作,一是由名为"Emu Edit"的模型完成灵活的图像编辑,支持通过文字编辑图像的各个方面,并确保编辑指令的准确... AI工具箱3年前
Meta多模态AI生图技术突破:静图秒变视频,逼真度媲美Gen-2 <img src=""> 新智元报道:AIGC动态欢迎阅读 近日,Meta公司发布了两项重磅研究成果,Emu Video和Emu Edit,引起了业界广泛关注。Emu Video是一种基于扩散模型的文本到视频生成方法,能够分解步骤生成高质量的视频,具有高度的风格化,使... AI工具箱3年前
港大推出强大的开源推荐系统新工具RLMRec,结合大模型技术,精准提炼用户和商品文本画像 近期港大发布了开源推荐系统新范式RLMRec,该系统结合了大语言模型的特点,能够更准确地提取用户和商品的文本画像。这一新的表征学习范式被成功应用于图神经网络的协同过滤推荐算法中,显著提高了推荐系统在推荐场景下的性能。传统的基于图神经网络的推荐算法主要依赖于ID数据构建的结构化拓扑信息,而忽视了推荐数... AI工具箱3年前
Meta推出Emu AI工具:革新图像与视频创作领域 <img src=""> 欢迎阅读AIGC动态 原标题:Meta发布Emu AI工具:革新图像和视频创作。关键词:图像、工具、社交、文本、编辑。文章来源:AI范儿。本文字数:2839字。内容摘要:Meta公司宣布推出Emu Edit和Emu Video两款AI内容创作... AI工具箱3年前
UNC斯坦福揭示GPT-4V意外漏洞:被人类哄骗数出8个葫芦娃!LeCun和Jim Fan震惊 最近,由新智元报道的一项研究指出GPT-4V存在严重漏洞,容易被欺骗出错误结果。据报道,这一模型甚至会在图像中误将吉娃娃认作松饼,甚至会被人类干扰而认为图中的葫芦娃数量为8个。然而,一些研究人员发现,只要对图像布局进行一些改变,GPT-4V就会再次陷入经典的计算机视觉难题,无法正确识别图像内容。 U... AI工具箱3年前
GPT-4V英雄联盟幻觉挑战:比葫芦娃还迷茫 <img src=""> 欢迎阅读AIGC动态 原文标题:连葫芦娃都数不明白,解说英雄联盟的GPT-4V面临幻觉挑战 关键词:偏见、图像、干扰、文本、幻觉 文章来源:机器之心 文章长度:6096字 文章摘要:机器之心的编辑张倩和小舟指出,让大型模型同时理解图像和文字可... AI工具箱3年前
DeepMind 破译希腊铭文:揭示千年密码新解读 <img src=""> 欢迎阅读AIGC动态 原标题:DeepMind破译希腊铭文:千年密码的新解读 关键词:铭文、解读、任务、文本、时间 文章来源:HyperAI超神经 字数:9511字 内容摘要:金石铭文和碑刻作为过去文明的体现,承载着古代思想、文化和语言。破译... AI工具箱3年前
Nature|AI检测器再次崛起!成功率高达98%,完胜OpenAI AI动态信息原文标题:《Nature》:AI检测器准确率高达98%,超越OpenAI关键词:检测器、文本、准确率、引言、学术期刊文章来源:新智元字数:8994字编辑:润 alan摘要:研究团队开发的学术AI内容检测器准确率高达98%,可能有效缓解AI论文泛滥问题。现有AI文本检测器难以区分AI生成文... AI工具箱3年前
李开复亲自推出零一万物大模型,AI 2.0 即将问世 AIGC动态欢迎阅读 以下内容为AI科技评论提供: 近日,李开复创办的AI 2.0公司零一万物发布了Yi系列模型,其中包含34B和6B两个版本。这次发布的模型在参数量和性能上都表现出色,尤其是Yi-34B,仅使用了不到LLaMA2-70B一半和Falcon-180B五分之一的参数量,却实现了对LLa... AI工具箱3年前
AI视频生成工具Gen-2全新升级:一句话生成4K超逼真视频,像素全面提升至最高水准 AIGC动态欢迎阅读原标题:AI视频生成工具Gen-2炸裂更新:一句话生成4K超逼真视频,像素一口气拉到最高逼格关键词:视频,创意,模型,效果,文本文章来源:夕小瑶科技说字数:4836字内容概要:夕小瑶科技说 分享来源 | 量子位这,绝对称得上是生成式AI进程中的里程碑。就在深夜,Runway家标志... AI工具箱3年前
单点端到端文本检测识别框架速度提升19倍:华科、华南理工等研究团队联合发布SPTS v2 本文介绍了华科、华南理工等联合发布的SPTS v2,该文本检测识别框架速度提升了19倍。近年来,场景文本阅读技术取得显著进步,能够同时定位和识别文本,在智慧办公、金融、交通等领域得到广泛应用。相较于目标检测,文本除了定位还需要精确识别内容,并且由于字体和排版的差异,文本实例可能呈现出任意形状,因此需... AI工具箱3年前
2023年最佳人工智能发明揭晓 <img src=""> 欢迎阅读AIGC动态 原标题:《时代》杂志发布:2023年最佳人工智能发明 关键词:人工智能、无人机、图像、文本、模型 文章来源:AI范儿 内容字数:7835 字 内容摘要:《时代》杂志评选出 2023 年度最佳发明,其中 14 个人工智能工... AI工具箱3年前
RLHF与AlphaGo合作,UW/Meta将文本生成技术提升至新高度 本文介绍了RLHF与AlphaGo的核心技术结合,如何借助UW/Meta的新解码算法使文本生成能力得到提升。研究者在近端策略优化训练的RLHF语言模型中应用了AlphaGo的蒙特卡洛树搜索算法,探讨了二者结合可能带来的创新和进步。文章来源于机器之心,想要查看原文可以点击原文链接。若需要联系作者,可以... AI工具箱3年前
波士顿动力机器狗搭载ChatGPT大脑,以老伦敦口音为游客导游 最新报道来自机器之心,介绍了波士顿动力将机器狗配备上LLM大脑,并通过ChatGPT技术实现对话功能,使其表现得像导游一样。在视频中,名为Spot先生的机器狗戴着高礼帽,有英国口音,引领人们参观公司设施。这一创新展示了机器狗的多功能,不仅可以攀爬、跳跃、跑酷、开门,还能说话引导游客。有兴趣可以点击原... AI工具箱3年前
DallE 3、Midjourney 5.2、SDXL、Firefly 2 和 Ideogram 比较指南 欢迎阅读AIGC动态 本文原标题为:“DallE 3、Midjourney 5.2、SDXL、Firefly 2 和 Ideogram 对比指南” 关键词包括:图像、模型、功能、提示、文本 文章来源:AI范儿 内容共计6721字,主要内容如下:本文比较了DALL-E 3、Midjourney 5.2... AI工具箱3年前
一行代码助力大型模型性能提升10%,开发者分享免费经验 在这则文章中,介绍了一种令大型模型性能提升的新方法。据悉,只需添加一行代码,即可使性能提升至少10%。甚至在参数数量为7B的Llama 2模型上,这一方法还能使性能翻倍,而Mistral模型也出现了四分之一的性能增长。研究人员提出了一种名为NEFT的微调方式,这是一种正则化技术,可用于提高微调监督。... AI工具箱3年前