EMNLP投稿数量近5000篇,北大、腾讯斩获最佳长论文奖 阅读AIGC动态的最新消息最新标题:EMNLP投稿近5000篇,北大、腾讯荣获最佳长论文奖关键词:腾讯、论文、研究者、上下文、效用文章来源:机器之心文章字数:6821字文章摘要:根据机器之心的报道,本届 EMNLP 大会在投稿数量上取得了新突破,并且整体接收率有所提升。EMNLP 是自然语言处理领域... AI工具箱3年前
揭秘:一句话引爆100k+上下文大模型潜能,27分提升至98,GPT-4、Claude2.1完美适用 <img src=""> 欢迎阅读AIGC动态 本文原标题为“一句话解锁100k+上下文大模型真实力,27分涨到98,适用于GPT-4和Claude2.1”。 关键词包括:测试、上下文、模型、公司、句子。 文章来源为《量子位》。 本文共计3272字。 内容摘要:最近,... AI工具箱3年前
北大微信AI联合团队再获EMNLP最佳长论文:揭秘大模型上下文学习机制 AIGC动态欢迎您的阅读 原文标题:中国团队再获EMNLP最佳长论文!北大微信AI联合揭秘大模型上下文学习机制 关键词:模型、标签、论文、信息、上下文 文章来源:量子位 文章字数:3701字 内容摘要:最近,北大微信AI团队荣获EMNLP顶会最佳长论文奖。该论文由北大的孙栩老师与微信的周杰、孟凡东共... AI工具箱3年前
贾佳亚团队新研究:AI成为鉴片大师,星际穿越也能轻松看懂超长3小时视频 AIGC动态欢迎阅读 本文来源于量子位,介绍了贾佳亚团队最新研究成果:他们开发的多模态大模型LLaMA-VID可以处理超长视频,使得AI能够像专业影评人一样理解电影,比如《星际穿越》,并对电影中的细节进行准确回答。这项研究的背后原理简单却高效,将每一帧图像的表示压缩到仅有2个token。与其他同类模... AI工具箱3年前
Llama 2 准确率提升至 80.3%:Meta 引入全新注意力机制 S2A,显著削减模型幻觉 本文介绍了Meta提出的全新注意力机制S2A,以大幅降低模型幻觉,提高了LLM回答问题的事实性和客观性。文章指出当前大型语言模型存在的问题,如偏见、幻觉、推理能力不足等,并探讨了新方法带来的改变。此外,文章提供了原文链接以供阅读。若想联系作者,可以通过微信号AI_era了解更多内容。整体内容来自新智... AI工具箱3年前
Claude 200K产品性能被严重「虚标」?1016美元实测后性能暴跌至90K 本文为《新智元》报道的一篇关于Claude 2.1模型的文章。根据报道,该模型在上下文长度达到90K后表现出明显的性能下降。此前有人投入1016美元测试后发现这一现象。与OpenAI不同,竞争对手Anthropic发布了支持200K上下文的Claude 2.1,它将原本强大的100K上下文能力提升了... AI工具箱3年前
Transformer架构再升级:Meta推出更智能的注意力机制 本文介绍了Meta针对Transformer架构进行的调整,尤其是引入了新的注意力机制,旨在增强推理能力。传统的大型语言模型(LLM)虽然功能强大,但有时仍会在推理方面表现不佳,容易受到不相关上下文或输入提示的影响。为了解决这一问题,Meta提出的System 2 Attention机制旨在更好地处... AI工具箱3年前
ChatGPT竞品最新升级:对话长度翻倍,API价格降低近三成 AIGC动态欢迎阅读 原文标题:ChatGPT最强竞争对手更新!上下文长度翻倍,API降价近30% 关键词:小米,上下文,版本,长度,幻觉 文章来源:量子位 内容字数:3741字 内容摘要:克雷西 发自 凹非寺量子位 | 公众号 QbitAI OpenAI开发者大会之后不久,ChatGPT的主要竞争... AI工具箱3年前
Anthropic发布Claude 2.1:让你在攻其不备中脱颖而出 欢迎阅读AIGC动态 本文原标题为:攻其不备:Anthropic发布Claude 2.1 关键词包括:上下文、模型、窗口、前身、答案 文章来源:AI范儿 全文共计3096字,内容摘要如下:Anthropic发布了Claude 2.1,拥有巨大的上下文窗口,提供更强大的语言模型和机器人。相对于其前身,... AI工具箱3年前
提升大模型能力:利用检索增强生成的Python实现指南 本文源自《机器之心》,介绍了如何通过检索增强生成(RAG)让大型语言模型(LLM)更加强大的内容。RAG的概念是利用外部知识源为LLM提供额外信息,使其可以生成更准确、符合上下文的答案,并减少幻觉。文章首先讨论了人们如何有效整合LLM的一般性知识与专有数据,引出了微调和RAG哪个更合适的讨论。随后详... AI工具箱3年前
哈工大华为联合打造的大型模型「幻觉」,详细解读就在这篇文章中! <img src=""> AI GC动态 欢迎阅读 原文标题:《大模型「幻觉」,看这一篇就够了 | 哈工大华为出品 关键词:幻觉,模型,上下文,小米,华为 文章来源:量子位 内容字数:7309字 内容摘要:最新系统综述探讨了大模型“幻觉”,全面阐述了幻觉的定义、分类、... AI工具箱3年前
1分钟诞生一个全新的GPT!3天内推出定制GPT,理想型男友、科研利器引爆全网热议 本文来自新智元的报道,题为《1分钟诞生一个新GPT!3天内定制GPT大爆发,理想型男友、科研利器全网刷屏》,全文6081字。在过去的短短3天里,全球见证了GPT应用的爆发,各种定制版GPT如雨后春笋般涌现,其增长速度远超预期。这说明了Altman在开发者大会上所言的“我们正在孕育新物种,它们正在迅速... AI工具箱3年前
GPT-4 Turbo开放给用户:速度快、效率高、节省成本 最近,OpenAI推出了GPT-4 Turbo,这是GPT-4模型的一个更加便宜、快速和智能的升级版本。新模型的成本大幅降低,并提供了更大的上下文窗口和扩展的API功能,包括图像处理和文本转语音。GPT-4 Turbo的发布标志着人工智能领域的一次重要进步,为未来技术发展奠定了基础。在OpenAI开... AI工具箱3年前
GPT4 Turbo的128K上下文实用性存疑?专家投入巨资评测,斯坦福论文提供支持 本文来自夕小瑶科技说,最近AI圈子里最受关注的话题之一是OpenAI在首届开发者日推出了GPT-4的加强版GPT-4 Turbo。GPT-4 Turbo带来了诸多升级,其中最引人注目的是上下文长度增至128K,相比GPT-4的32K上下文长度,提升了四倍。对于GPT-4 Turbo的这一升级,有人质... AI工具箱3年前
OpenAI首届AI春晚:创业公司之夜,GPT-4大爆更新,API价暴跌! <img src=""> 专题:AIGC动态 这是一则关于OpenAI的最新动态。OpenAI的首届AI开发者大会吸引了众多创业公司参与,会上发布了强大的GPT-4 Turbo模型,以帮助开发者创作并实现盈利。此外,API定价也有大幅度调整,让人热情高涨。 关键词:模... AI工具箱3年前
马斯克发布第二款AI产品PromptIDE,Grok的开发紧密依赖于它 最近,马斯克发布了第二款AI产品PromptIDE,这是xAI团队推出的另一款人工智能产品。这款产品是一个集成开发环境,可用于prompt工程和解释性研究。不久之前才发布了Grok,现在又有了这个全新的产品,看来xAI团队的开发速度确实惊人。PromptIDE的推出再次引起了人们对xAI团队的关注,... AI工具箱3年前
DeepMind称Transformer模型泛化能力受预训练数据限制,引发质疑 本文报道来自机器之心的一篇关于DeepMind指出Transformer在超出预训练数据范围时无法实现泛化能力的文章。该文章探讨了大语言模型在提供上下文样本的情况下,通过输入生成响应的能力,以及Transformer模型在这一过程中的作用。同时,对于Transformer无法在预训练数据之外实现泛化... AI工具箱3年前
OpenAI正式发布强大的ChatGPT-4,全新升级版GPT商店现已上线,价格大幅优惠! AIGC动态欢迎阅读 近日,OpenAI宣布推出更强大的GPT-4,并将在“GPT商店”上线该产品,价格更为亲民。这一消息引发了业界的高度关注。 ChatGPT在首届开发者日上推出了定制版GPT,CEO山姆·奥特曼现场演示了“创业导师GPT”的惊人能力。这一版本的GPT可根据用户需求进行个性化定制,... AI工具箱3年前
OpenAI推出更强GPT-4、GPT商店、Agent工具、API降价!助您抢占AI生态位 AIGC动态欢迎阅读 原题:抢占生态位!更强GPT-4、GPT商店、Agent工具、API降价!OpenAI开发者大会开启AI大规模落地 关键词:报告、开发者、模型、函数、上下文 文章来源:Founder Park 字数:4904字 内容摘要:OpenAI DevDay被誉为首届AI春晚,在旧金山举... AI工具箱3年前
ChatGPT再升级!全新的GPT-4版本正式发布,API价格大幅下调,发布会现场掌声连连 AIGC动态欢迎阅读本文来源自量子位,介绍了ChatGPT王炸升级的消息。OpenAI在首届开发者日上发布了更强版本的GPT-4,并将推出“GPT商店”与创作者分享收入。CEO山姆·奥特曼亲自演示了如何使用定制GPT创建“创业导师GPT”,引起了现场观众的热烈掌声。新的GPT不仅可以在公司内部分享,... AI工具箱3年前
李开复亲自推出零一万物大模型,AI 2.0 即将问世 AIGC动态欢迎阅读 以下内容为AI科技评论提供: 近日,李开复创办的AI 2.0公司零一万物发布了Yi系列模型,其中包含34B和6B两个版本。这次发布的模型在参数量和性能上都表现出色,尤其是Yi-34B,仅使用了不到LLaMA2-70B一半和Falcon-180B五分之一的参数量,却实现了对LLa... AI工具箱3年前
零一万物发布全球首个开源模型,李开复详解AI 2.0的商业思维 <img src="">AIGC动态欢迎阅读原标题:零一万物发布全球首个开源模型,李开复探讨AI 2.0商业思维关键词:模型、万物、文本、上下文、能力文章来源:创始人公园文章长度:6286字内容摘要:李开复于3月提出AI 2.0,认为大型模型将带来平台级创新机会,重新... AI工具箱3年前
李开复发布「全球最强」开源大模型:支持处理40万汉字,同时中英双语霸榜 AIGC动态欢迎阅读 原文标题:李开复正式宣布推出“全球领先”的开源大型模型:同时处理40万汉字,中英文双语霸榜 关键词:模型、万物、上下文、窗口、能力 文章来源:机器之心 内容字数:4833字 内容摘要:编辑部门刊机器之心报道中提到,李开复在正式宣布“零一万物”大型模型公司进军全球大模型领域的第一... AI工具箱3年前
OpenAI DevDay活动提前曝光了大量新功能信息 在此处是一篇关于OpenAI DevDay的文章内容。根据原始信息,OpenAI DevDay即将发布的ChatGPT创新功能包括全新用户界面、自定义机器人工具Gizmo、企业订阅计划、工作区功能和上下文连接器。这些升级将推动ChatGPT在人工智能消费市场上迈向新的高度。即将举行的OpenAI首次... AI工具箱3年前
OpenAI揭秘:王者GPT-4横空出世,拥有32k上下文,首次亮相开发者大会! 在新智元报道中,报道了OpenAI首届开发者大会的最新爆料。ChatGPT推出了全新的UI界面,使得每个人都能够自定义GPT,这将带动“智能体工程师”这一新职业的诞生。同时,马斯克的xAI大型模型也已经开始了广泛的内测。在这个备受关注的开发者大会上,ChatGPT的两大新能力也悄然揭晓:一是可以上传... AI工具箱3年前
OpenAI首届开发者大会揭开面纱:全新ChatGPT原型Gizmo曝光 本文来源于机器之心,报道编辑为杜伟和大盘鸡。OpenAI首席执行官Sam Altman宣布了首届开发者大会「OpenAI DevDay」的消息。在这次大会上,OpenAI团队将与全球开发者分享全新的AI工具。虽然Sam Altman表示不会发布GPT-5或GPT-4.5等产品,但仍承诺会推出一些非常... AI工具箱3年前
马斯克“曝光”幽默感爆棚的xAI「阴阳怪气」大模型,ChatGPT重大更新提前曝光 最新动态:AIGC引人关注原文题目:特斯拉创始人突然公布xAI「幽默十足」大型模型,令人捧腹大笑!ChatGPT迎来重大更新提前曝光关键词:机器人,上下文,工作,模型资讯来源:新智元字数统计:全文共4512字内容摘要:新智元报道编辑:好困 Aeneas【新智元导读】特斯拉创始人推出xAI大型模型,将... AI工具箱3年前
Baichuan2-192K:全球最强大长文本模型,一次可识别35万汉字 近日,国内大模型创业公司百川智能正式发布了Baichuan2-192K长窗口大模型,这一消息备受关注。该模型拥有前所未有的处理能力,一次可读取长达35万汉字的文本,将大语言模型(LLM)上下文窗口的长度提升至192K token。这意味着,相较于GPT-4(32K token,约2.5万字),Bai... AI工具箱3年前
百川智能新品发布:Baichuan2-192K上下文窗口最长,一次超越Claude2输入35万字 AIGC动态欢迎阅读 本文转载自量子位,原标题为:“百川智能推出全球最长上下文窗口大模型Baichuan2-192K,一次可输入35万字超越Claude2”。文章介绍了新发布的Baichuan2-192K大模型,其上下文窗口长度达到192K,是目前全球最长的上下文窗口之一。Baichuan2-192... AI工具箱3年前
Meta普林斯顿提出LLM上下文终极解决方案:让模型成为自主智能体,自行阅读上下文节点树 <img src=""> AI动态分享 原标题:Meta普林斯顿提出LLM上下文终极解决方案!让模型化身自主智能体,自行读取上下文节点树。 关键词:节点,团队,上下文,内存,基线。 文章来源:新智元 内容字数:9800字 内容摘要:新智元报道编辑:润。LeCun转发了... AI工具箱3年前
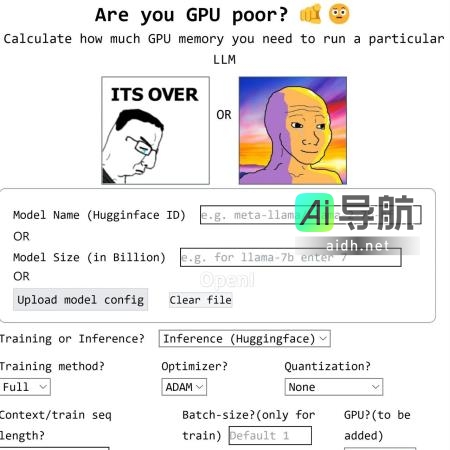
测试你的GPU是否能够运行Llama 2等大模型,快来试试这个开源项目吧 此文介绍了一个开源项目,可以帮助用户测试他们的GPU是否能够运行大模型,比如LLama 2。在GPU算力至关重要的今天,许多人很难确定他们的GPU是否足够强大来运行大型模型。本文提到了一个项目,可以帮助用户提前查看自己的GPU内存是否足够。文章来源于《机器之心》,作者是陈萍,内容字数为3295字。读... AI工具箱3年前
UC伯克利团队发布MemGPT大模型的上下文内存管理方案,同时开源AgentLM、多模态Fuyu-8B以及数学LLEMMA等专用大模型 <img src=""> 【AIGC动态】欢迎阅读 原标题:UC伯克利团队开源MemGPT大模型上下文内存管理方案;AgentLM、多模态Fuyu-8B、数学LLEMMA等专用大模型开源 关键词:模型、数据、上下文、能力、智能 文章来源:机器之心 内容字数:9138字... AI工具箱3年前
LLaMA2模型上下文长度扩展至100万tokens,仅需调整一个超参数|复旦邱锡鹏团队力作 AI 前沿信息 原标题:复旦邱锡鹏团队调整一个超参数,LLaMA2上下文长度达100万tokens 关键词:模型、长度、位置、底数、上下文 文章来源:量子位 字数:5019 字 内容摘要:最新研究发现,只需微调一个超参数,LLaMA 2 模型上支持的上下文长度从1.6 万 tokens 延长至 10... AI工具箱3年前
英伟达发布了最新开源Agent:利用GPT-4训练的机器人,在处理越复杂任务时表现更加出色 欢迎阅读AIGC动态 以下内容来自量子位: 近日,英伟达发布了最新的AI Agent - Eureka,该Agent通过GPT-4训练,表现出色。使用生成奖励函数的方法,Eureka完成了超过三十个复杂任务,包括快速转笔、打开抽屉和柜子、抛掷和接球等。其中,转笔这一技能尤为引人注目,因为即使是人类逐... AI工具箱3年前
将LLM视作操作系统,它获得无限的「虚拟」上下文,伯克利新作已获1.7k星称赞 欢迎阅读AIGC动态原标题:将LLM视为操作系统,赋予其无限"虚拟"上下文,伯克利的新作已收获1.7k星关键词:上下文,研究者,智能,任务,下文文章来源:机器之心内容字数:6439字内容摘要:机器之心编辑:杜伟、小舟如今,赋予大型语言模型更强大的上下文处理能力是业界极为关注的热点。本文介绍了加州大学... AI工具箱3年前
优化基础LLM技术:Meta版ChatGPT为长上下文提供持续预训练 AIGC动态欢迎阅读 原标题:「Meta版ChatGPT」背后的技术:持续预训练改进基础LLM处理长上下文的能力 关键词:模型、上下文、长上、任务、下文 文章来源:机器之心 内容字数:10932字 内容摘要:机器之心报道编辑 Panda W 在处理长上下文方面指出,LLaMA 在一直力有不足,而通过... AI工具箱3年前
抛弃「浪费」GPU,FlashAttention重磅升级,长文本推理速度提升8倍 在机器之心报道中,编辑部使用大型模型处理长文本,面临着速度挑战。最新的FlashAttention技术通过"Flash-Decoding"方法,充分利用GPU,可以将大模型的长上下文推理速度提高至8倍。近期大型语言模型(LLM)如ChatGPT和Llama备受关注,但其运行成本仍... AI工具箱3年前
AI 天才杨植麟发布长模型产品,特点:长长长长长 <img src=""> AI模型革新:杨植麟打造超长文本产品 原标题:AI 天才杨植麟推出长篇大作 关键词:模型、上下文、清华、文本长度 文章来源:量子位 文章字数:8018字 内容摘要:杨植麟推出的万字级大模型产品支持长达20万字的文本输入,堪称全球最长。此举刷新... AI工具箱3年前
杨植麟:千亿大模型迈入“长文本”时代,支持20万字输入 | 甲子光年 本文介绍了关于杨植麟及其在大模型和长文本领域的重要性的内容。杨植麟作为中国AI领域的重要人物之一,其在自然语言处理领域的突出贡献备受瞩目。文章详细介绍了他在科技领域的影响力和重要性。如需了解更多相关信息,请阅读原文链接。同时,文末提供了作者的联系方式和个人简介,为读者提供更多深入了解的机会。 AI工具箱3年前
杨植麟的新公司打造世界最大对话框容量,引领大模型「长」时代 欢迎阅读AIGC动态 原标题:大规模模型引领“长”时代,杨植麟的新公司将对话框容量提升至全球领先地位。 关键词:模型、上下文、窗口、解读、能力 文章来源:机器之心 内容字数:11427字 内容摘要:近日,大规模模型初创公司Anthropic成功获得了亚马逊的投资,成为引领大规模模型领域的一大事件。与... AI工具箱3年前