最近,AI 领域迎来了一项重要的更新:Stable Video Diffusion模型的问世。Stability AI 公司推出了这一视频生成模型,给人们留下了深刻印象。该模型继承了公司原有的 Stable Diffusion 文生成图模型,现在用户们有机会基于静止图像生成短视频。Stable Vi...
本文介绍了复旦大合华为诺亚提出的VidRD框架,旨在实现迭代式的高质量视频生成。文章来源于机器之心,总字数为6382字。该框架名为“Reuse and Diffuse”,基于图像扩散模型(LDM)实现在已经生成的少部分视频帧之后,产生更多视频帧的功能,从而生成更长、更高质量以及多样化的视频内容。若想...
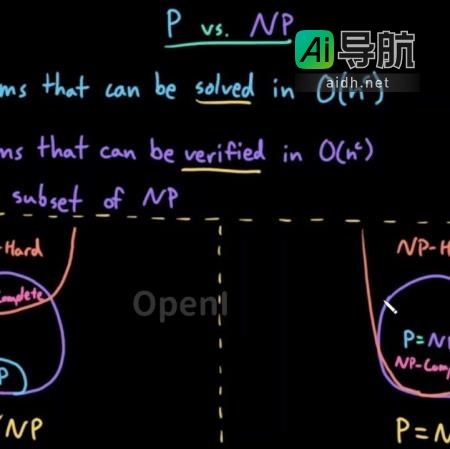
最新动态:最新文章分享原标题:GPT-4在97轮对话中探索世界难题,得出P≠NP结论关键词:问题、模式、框架、递归、本文文章来源:机器之心文章长度:3960字内容简介:这篇文章对“LLM for Science”进行了一次有希望的探索。对于从事科研工作的人来说,多少都听说过P/NP问题,这个问题被克...