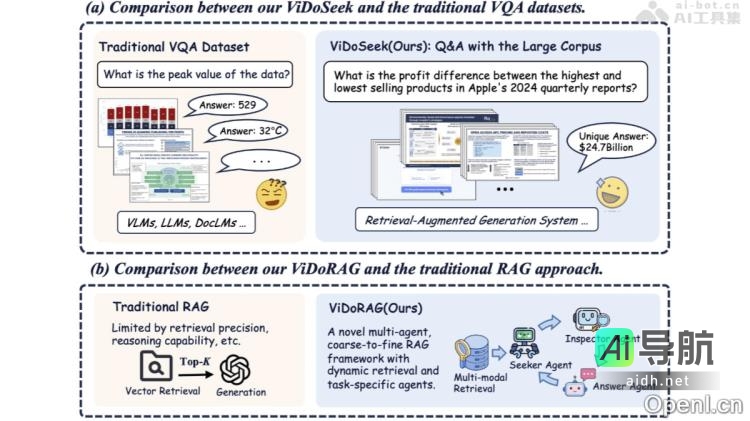
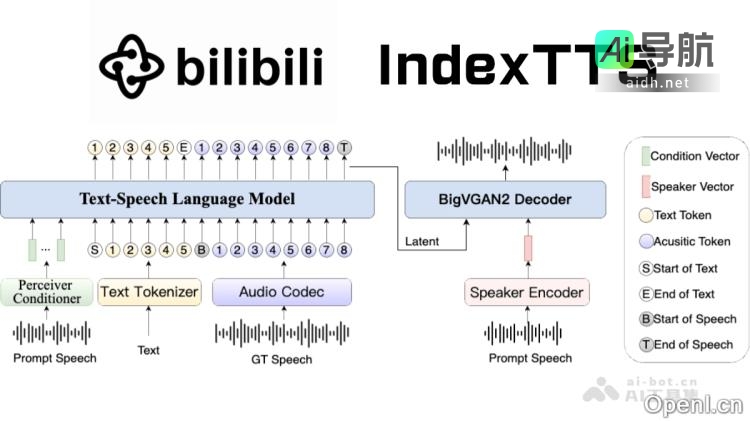
Mistral OCR 是 Mistral AI 最新推出的一款光学字符识别(OCR)工具,专为处理复杂文档而设计。该工具能够全面解析文档中的文本、图像、表格和数学公式,支持多种语言和字体,准确率高达99.02%。在各项基准测试中,Mistral OCR 的表现超越了 Google Document...
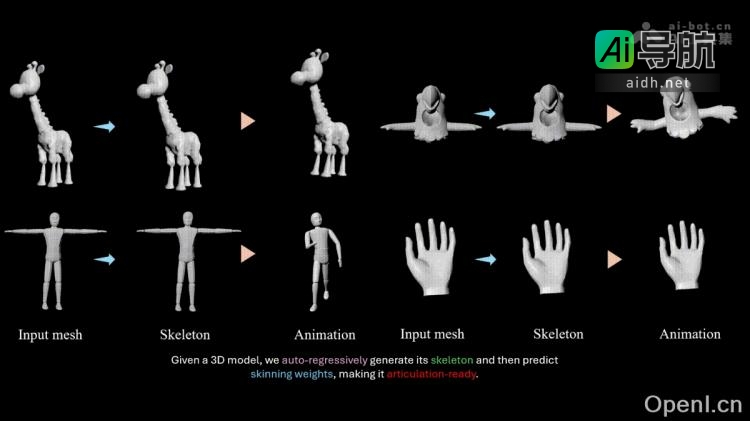
智元机器人推出了一款名为AgiBot Digital World的机器人仿真框架,旨在支持机器人操作技能的研究与应用。这一框架结合了大量真实的三维资产、多样化的专家轨迹生成机制以及全面的模型评估工具,通过高度逼真的模拟和全链路的自动化数据生成,能够快速构建多样化的机器人训练场景。 AgiBot Di...
Pika 2.2是由Pika Labs最新推出的升级版AI视频生成工具。利用深度学习技术,将图像或文字提示转换为高质量的视频内容。与旧版本相比,Pika 2.2在功能和性能上都有显著提升。支持生成长达10秒的视频,并提供1080p的高清分辨率。此外,引入了"Pikaframes"功能,通过关键帧过渡...
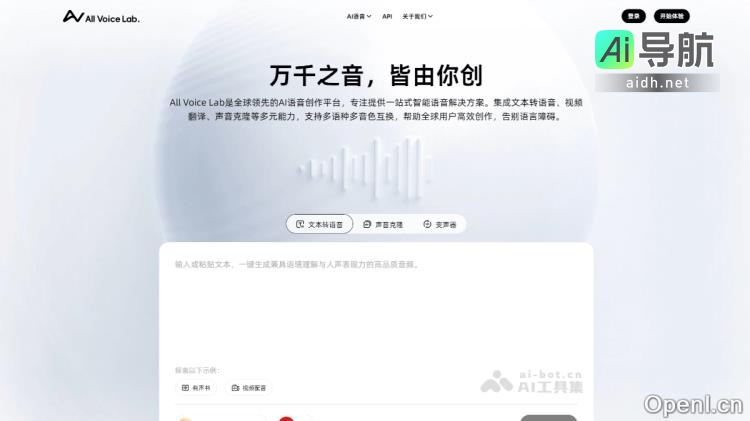
All Voice Lab是一个全球领先的AI语音创作平台,致力于为用户提供一站式的智能语音解决方案。该平台基于趣丸科技与香港中文大学(深圳)共同研发的MaskGCT语音大模型,旨在帮助全球创作者跨越语言和技术障碍,实现内容创作和国际传播的高效性。All Voice Lab支持中文、英语、法语、德语...
Miss Dora是针对3至8岁儿童设计的AI英文阅读应用,旨在通过个性化的故事讲述和互动问答激发孩子的阅读热情与想象力。该应用拥有丰富的故事库,覆盖多个阅读水平,旨在支持孩子的学习,减轻家长的讲故事负担。Miss Dora融合了传统阅读和现代科技,为孩子们提供有趣而具有教育意义的学习体验。 Mis...